Neste capítulo vamos apresentar alguns métodos gerais para gerarmos realizações de variáveis aleatórias de outras distribuições de probabilidade, como, por exemplo, dos modelos exponencial, normal e binomial. Implementaremos algumas funções em Python e finalizaremos com a apresentação das rotinas otimizadas e já implementadas.
3.1 Introdução
Vamos estudar a partir deste instante um dos principais métodos, determinado pela lei fundamental de transformação de probabilidades, para gerarmos dados de distribuições de probabilidades contínuas ou discretas. Para alguns casos específicos, vamos ilustrar com procedimentos alternativos, que sejam eficientes e computacionalmente mais simples. Esta transformação tem como modelo fundamental a distribuição uniforme \((0\), \(1)\). Por essa razão a geração de números uniformes contínuos é tão importante.
Veremos posteriormente nestas notas de aulas algoritmos para obtermos numericamente a função de distribuição \(F(x)\) e a sua função inversa \(x = F^{-1}(p)\), em que \(p\) pertence ao intervalo que vai de \(0\) a \(1\). Este conhecimento é fundamental para a utilização deste principal método.
Neste capítulo limitaremos a apresentar a teoria para alguns poucos modelos probabilísticos, para os quais podemos facilmente obter a função de distribuição de probabilidade e a sua inversa analiticamente. Para os modelos mais complexos, embora o método determinado pela lei fundamental de transformação de probabilidades seja adequado, apresentaremos apenas métodos alternativos, uma vez que, em geral, ele é pouco eficiente em relação ao tempo gasto para gerarmos cada realização da variável aleatória. Isso se deve ao fato de termos que obter a função inversa numericamente da função de distribuição de probabilidade dos modelos probabilísticos mais complexos.
3.2 Métodos Gerais para Gerar Realizações de Variáveis Aleatórias
Podemos obter realizações de variáveis aleatórias de qualquer distribuição de probabilidade a partir de números aleatórios uniformes. Para isso um importante teorema pode ser utilizado: o teorema fundamental da transformação de probabilidades.
Theorem 3.1 (Teorema fundamental da Transformação de Probabilidades) Sejam \(U\) uma variável uniforme \(U(0, 1)\) e \(X\) uma variável aleatória com densidade \(f\) e função de distribuição \(F\) contínua e invertível, então \(X=F^{-1}(U)\) possui densidade \(f\). Sendo \(F^{-1}\) a função inversa da função de distribuição \(F\).
Demonstração: Seja \(X\) uma variável aleatória com função de distribuição \(F\) e função densidade \(f\). Se \(u=F(x)\), então o jacobiano da transformação é \(du/dx=F'(x)=f(x)\), em que \(U\) é uma variável aleatória uniforme \(U(0, 1)\), com função densidade \(g(u)=1\), para \({0<u<1}\) e \(g(u)=0\) para outros valores de \(u\). Assim, a variável aleatória \(X=F^{-1}(U)\) tem densidade \(f\) dada por:
\[f_X(x)=g(u) \left|\frac{du}{dx}\right| = g\left(F_X(x)\right)f(x)=f(x).\] Em outras palavras a variável aleatória \(X=F^{-1}(U)\) possui função densidade \(f_X(x)\), estabelecendo o resultado almejado e assim, a prova fica completa. \(\blacksquare\)
Para variáveis aleatórias discretas, devemos modificar o teorema para podermos contemplar funções de distribuições \(F\) em escada, como são as funções de distribuição de probabilidades associadas a essas variáveis aleatórias.
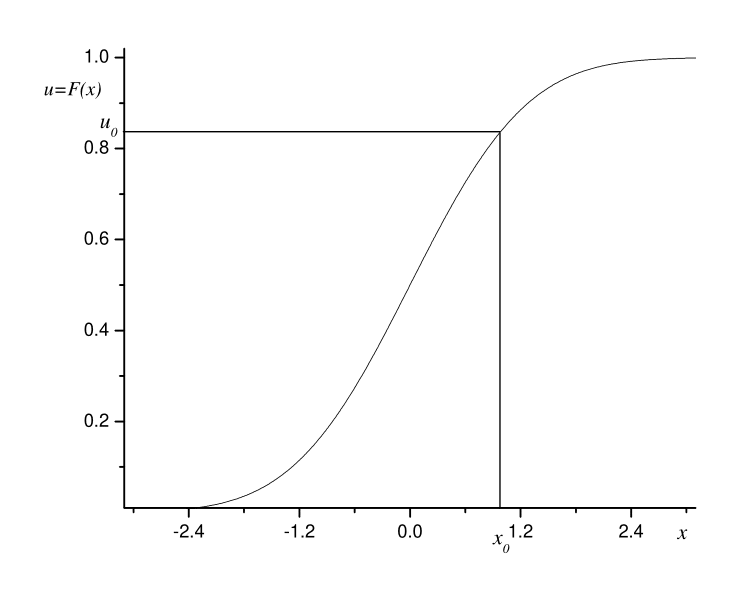
Na Figura Figure 3.1 representamos como gerar uma realização de uma variável aleatória \(X\) com densidade \(f\) e função de distribuição \(F\). Assim, basta gerarmos um número uniforme \(u_0\) e invertermos a função de distribuição \(F\) neste ponto. Computacionalmente a dificuldade é obtermos analiticamente uma expressão para a função \(F^{-1}\) para muitos modelos probabilísticos. Em geral, essas expressões não existem e métodos numéricos são requeridos para inverter a função de distribuição. Neste capítulo vamos apresentar este método para a distribuição exponencial.
Figure 3.1: Ilustração do teorema fundamental da transformação de probabilidades para gerar uma variável aleatória \(X\) com densidade \(f(x)=F'(x)\). A partir de um número aleatório uniforme \(u_0\) a função de distribuição é invertida neste ponto para se obter \(x_0\), com densidade \(f(x)\).
Outro método bastante geral que utilizaremos é denominado de método da amostragem por rejeição. Esse método tem um forte apelo geométrico. Procuraremos, a princípio, descrever esse método de uma forma bastante geral. Posteriormente, aplicaremos este método para gerarmos variáveis aleatórias de alguns modelos probabilístico. A grande vantagem deste método contempla o fato de não precisarmos obter a função de distribuição de probabilidade e nem a sua inversa. Estas estratégias só podem ser aplicadas em muitos dos modelos probabilísticos existentes, se utilizarmos métodos numéricos iterativos. Seja \(f(x)\) a função densidade de probabilidade para a qual queremos gerar uma amostra aleatória. A área sob a curva para um intervalo qualquer de \(x\) corresponde à probabilidade de gerar um valor \(x\) nesse intervalo. Se pudéssemos gerar um ponto em duas dimensões, digamos \((X,Y)\), com distribuição uniforme sob a área, então a coordenada \(X\) teria a distribuição desejada.
Para realizarmos de uma forma eficiente a geração de realizações variáveis aleatórias com densidade \(f(x)\), evitando as complicações numéricas mencionadas anteriormente, poderíamos definir uma função qualquer \(g(x)\). Essa função tem que ter algumas propriedades especiais para sua especificação. Deve possuir área finita e ter para todos os valores \(x\) densidade \(g(x)\) superior a \(f(x)\). Essa função é denominada de função de comparação. Outra característica importante que \(g(x)\) deve ter é possuir função de distribuição \(G(x)\) analiticamente computável e invertível, ou seja, \(x=G^{-1}(u)\). Como a função \(g(x)\) não é necessariamente uma densidade, vamos denominar a área sob essa curva no intervalo para \(x\) de interesse por \(A=\int_{-\infty}^{\infty}g(x)dx\). Como \(G^{-1}\) é conhecida, podemos gerar pontos uniformes \((x,y)\) que pertencem à área sob a curva \(g(x)\) facilmente. Para isso basta gerarmos um valor de uma variável aleatória uniforme \(u_1\) entre \(0\) e \(A\) e aplicarmos o teorema (Theorem 3.1). Assim, obtemos o primeiro valor do ponto \((x_0,y_0)\) por \(x_0=G^{-1}(u_1)\). Para gerarmos a segunda coordenada do ponto não podemos gerar um valor de uma variável aleatória uniforme no intervalo de \(0\) a \(A\), sob pena de gerarmos um ponto que não está sob a curva \(g(x)\). Assim, calculamos o valor de \(g\) no ponto \(x_0\) por \(g(x_0)\). Geramos \(y_0=u_2\), sendo \(u_2\) o valor de uma variável aleatória uniforme entre \(0\) e \(g(x_0)\). Assim, obtemos um ponto \((x_0,y_0)\) uniforme sob a curva \(g(x)\). A dificuldade deste método é justamente estabelecer essa função \(g(x)\) com as propriedades exigidas.
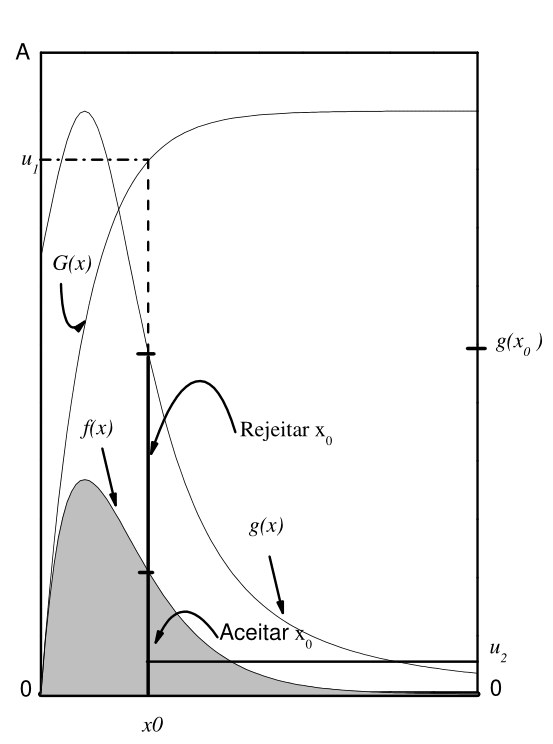
Vamos agora traçar as curvas correspondentes a \(g(x)\) e \(f(x)\) no mesmo gráfico. Se o ponto uniforme \((x_0,y_0)\) está na área sob a curva \(f(x)\), ou seja se \(y_0 \le f(x_0)\), então aceitamos \(x_0\) como um valor válido de \(f(x)\); se por outro lado o ponto estiver na região entre as densidades \(f(x)\) e \(g(x)\), ou seja se \(f(x_0)<y_0 \le g(x_0)\), então rejeitamos \(x_0\). Uma forma alternativa de apresentarmos esse critério é tomarmos \(y_0\) de uma distribuição \(U(0,1)\) e aceitarmos ou rejeitarmos \(x_0\) se \(y_0 \le f(x_0)/g(x_0)\) ou se \(y_0 > f(x_0)/g(x_0)\), respectivamente. Ilustramos esse método na Figura Figure 3.2, sendo que a \(A\) representa a área total sob a curva \(g(x)\).
Figure 3.2: Método da rejeição para gerar um valor \(x_0\) da variável aleatória \(X\) com função densidade \(f(x)\) que é menor do que \(g(x)\) para todo \(x\). Nessa ilustração, \(x_0\) deve ser aceito.
Vamos ilustrar o primeiro método e salientar que o segundo método é o que ocorre na maioria dos casos de geração de variáveis aleatórias. A exponencial é uma distribuição de probabilidade em que facilmente podemos aplicar o teorema Theorem 3.1 para gerarmos amostras aleatórias. Assim, optamos por iniciar o processo de geração de números aleatórios nesta distribuição, uma vez que facilmente podemos obter a função de distribuição e a sua inversa. Seja \(X\) uma variável aleatória cuja densidade apresentamos por: \[
f(x)=\lambda e^{-\lambda x}
\tag{3.1}\] em que \(\lambda>0\) é o parâmetro da distribuição exponencial e \(x>0\).
A função de distribuição exponencial é dada por: \[F(x)=\int_{0}^{x}\lambda e^{-\lambda t}dt\]
\[
F(x)=1-e^{-\lambda x}.
\tag{3.2}\]
A função de distribuição inversa \(x=F^{-1}(u)\) é dada por:
\[
x=F^{-1}(u)=\frac{-\ln(1-u)}{\lambda}
\tag{3.3}\] em que \(u\) é um número uniforme \((0, 1)\).
Devido à distribuição uniforme ser simétrica, podemos substituir \(1-u\) na equação (Equation 3.3) por \(u\). Assim, para gerarmos uma realização de uma variável exponencial \(X\), a partir de uma variável aleatória uniforme, utilizamos o teorema Theorem 3.1 por intermédio da equação: \[
x=\frac{-\ln(u)}{\lambda}.
\tag{3.4}\]
O algoritmo Python para gerarmos realizações de variáveis aleatórias exponenciais é dado por:
# programa demonstrando a geração de n realizações de variáveis# aleatórias exponenciais com parâmetro lamb, utilizamos# a função np.random.uniform() para# gerarmos números aleatórios uniformesimport numpy as npdef rexpon(n, lamb =1.0): u = np.random.uniform(0.0, 1.0, n) # gera vetor u (U(0,1)) x =-np.log(u) / lamb # gera vetor x com distrib. exp.return x # retorna o vetor x# exemplorexpon(5, 0.1)
Podemos utilizar a função pré-existente do Python (np.random.exponential(scale=1.0, size=None)) para realizarmos a mesma tarefa. Simplesmente digitamos np.random.exponential(scale=10, size=5) e teremos uma amostra aleatória de tamanho \(n\) de uma exponencial com parâmetro \(\lambda=1/\textrm{scale}\). O Python faz com que a estatística computacional seja ainda menos penosa e portanto acessível para a maioria dos pesquisadores.
3.3 Variáveis Aleatórias de Algumas Distribuições Importantes
Vamos descrever nesta seção alguns métodos específicos para gerarmos algumas realizações de variáveis aleatórias. Vamos enfatizar a distribuição normal. Apesar de o mesmo método apresentado na seção Section 3.2 poder ser usado para a distribuição normal, daremos ênfase a outros processos. Para utilizarmos o mesmo método anterior teríamos que implementar uma função parecida com rexpon, digamos rnormal. No lugar do comando x = -log(u)/lamb deveríamos escrever \(x=\textrm{invnorm}(u)\times\sigma + \mu\), sendo que invnorm(u) é a função de distribuição normal padrão inversa. A distribuição normal padrão dentro da família normal, definida pelos seus parâmetros \(\mu\) e \(\sigma^2\), é aquela com média nula e variância unitária. Esta densidade será referenciada por \(N(0,1)\). Essa deve ser uma função externa escrita pelo usuário. Os argumentos \(\mu\) e \(\sigma\) da função são a média e o desvio padrão da distribuição normal que pretendemos gerar. A função densidade da normal é:
Nenhuma outra função utilizando o teorema Theorem 3.1 será novamente apresentada, uma vez que podemos facilmente adaptar as funções rexpon se tivermos um eficiente algoritmo de inversão da função de distribuição do modelo probabilístico alvo. A dificuldade deste método é a necessidade de uma enorme quantidade de cálculo para a maioria das densidades. Isso pode tornar ineficiente o algoritmo, pois o tempo de processamento é elevado.
Podemos ainda aproveitar a relação entre algumas funções de distribuições para gerarmos realizações de variáveis aleatórias de outras distribuições. Por exemplo, se \(X\) é normal com densidade (Equation 3.5), \(N(\mu,\sigma^2)\), podemos gerar realizações de \(Y=e^X\). Sabemos que fazendo tal transformação \(Y\) terá distribuição log-normal, cuja densidade com parâmetros de locação \(\alpha\)\((\mu)\) e escala \(\beta\)\((\sigma)\) é:
Um importante método usado para gerar dados da distribuição normal é o de Box-Müller, que é baseado na generalização do método da transformação de variáveis para mais de uma dimensão. Para apresentarmos esse método, vamos considerar \(p\) variáveis aleatórias \(X_1\), \(X_2, \ldots ,\)\(X_p\) com função densidade conjunta \(f(x_1,x_2, \ldots, x_p)\) e \(p\) variáveis \(Y_1\), \(Y_2\), \(\ldots\), \(Y_p\), funções de todos os \(X\)’s, então a função densidade conjunta dos \(Y\)’s é:
\[
f(y_1, \ldots , y_p)=f(x_1, \ldots, x_p) \textrm{abs}\left|
\begin{array}{ccc}
\frac{\partial x_1}{\partial y_1} & \ldots & \frac{\partial x_1}{\partial y_p} \\
\vdots & \ddots & \vdots \\
\frac{\partial x_p}{\partial y_1} & \ldots & \frac{\partial x_p}{\partial y_p}
\end{array}
\right|
\tag{3.7}\] em que \(J=\left| \partial()/\partial()\right|\) é o Jacobiano da transformação dos \(X\)’s em relação aos \(Y\)’s.
Vamos considerar a transformação (Equation 3.7) para gerar dados normais com densidade dadas por (Equation 3.5). Para aplicarmos a transformação de Box-Müller, vamos considerar duas variáveis aleatórias uniformes entre \(0\) e \(1\), representados por \(X_1\) e \(X_2\) e duas funções delas, representadas por \(Y_1\) e \(Y_2\) e dadas por:
Sabendo que a seguinte derivada \(d k\arctan(g)/d x\) é dada por \(k(d g/d x)/(1+g^2)\), em que \(g\) é uma função de \(X\), então o Jacobiano da transformação é:
Desde que a densidade conjunta de \(Y_1\) e \(Y_2\) é o produto de duas normais independentes, podemos afirmar que as duas variáveis geradas são normais padrão independentes, como pode ser visto em Johnson and Wichern (1998) e Ferreira (2018).
Assim, podemos usar esse resultado para gerarmos variáveis aleatórias normais. A dificuldade, no entanto, é apenas computacional. A utilização de funções trigonométricas como seno e cosseno pode limitar a performance do algoritmo gerado tornando-o lento. Um truque apresentado em Press et al. (1992) é bastante interessante para evitarmos diretamente o uso de funções trigonométricas. Esse truque representa uma melhoria do algoritmo de Box-Müller e é devido a Marsaglia and Bray (1964).
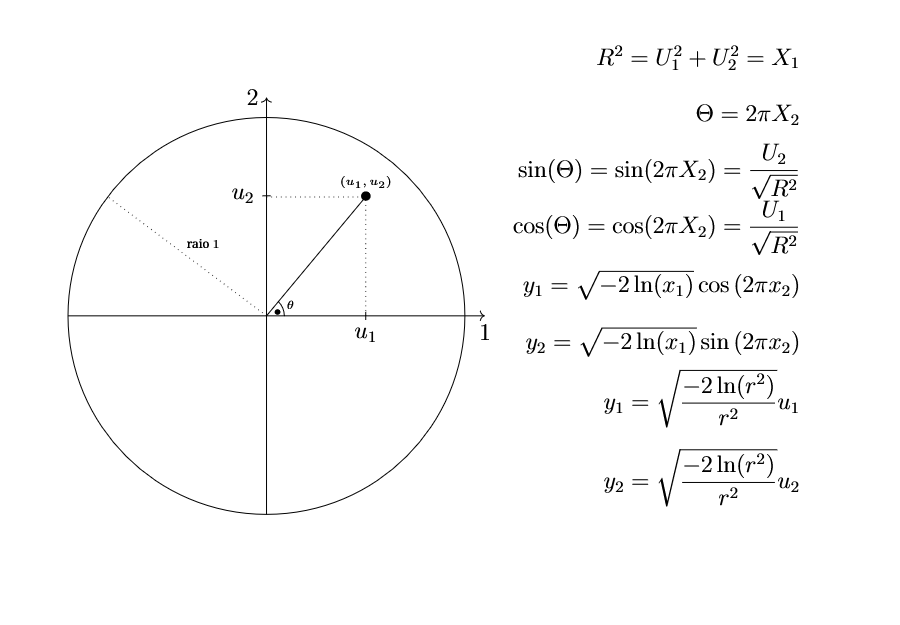
Ao invés de considerarmos os valores das variáveis aleatórias uniformes \(x_1\) e \(x_2\) de um quadrado de lado igual a \(1\) (quadrado unitário), tomarmos \(u_1\) e \(u_2\) como coordenadas de um ponto aleatório em um círculo unitário (de raio igual a \(1\)). A soma de seus quadrados \(R^2=U_1^2+U_2^2\) é uma variável aleatória uniforme que pode ser usada como \(X_1\). Já o ângulo que o ponto \((u_1, u_2)\) determina em relação ao eixo \(1\) pode ser usado como um ângulo aleatório dado por \(\Theta=2\pi X_2\). Podemos apontar que a vantagem da não utilização direta da expressão (Equation 3.8) refere-se ao fato do cosseno e do seno poderem ser obtidos alternativamente por: \(\cos{(2\pi x_2)}=u_1/\sqrt{r^2}\) e \(\sin{(2\pi x_2)}=u_2/\sqrt{r^2}\). Evitamos assim as chamadas de funções trigonométricas. Na Figura Figure 3.3 ilustramos os conceitos apresentados e denominamos o ângulo que o ponto \((u_1,u_2)\) determina em relação ao eixo \(u_1\) por \(\theta\).
Figure 3.3: Círculo unitário mostrando um ponto aleatório \((u_1\), \(u_2)\) com \(r^2\)\(=\)\(u_1^2\)\(+\)\(u_2^2\) representando \(x_1\) e \(\theta\) o ângulo que o ponto \((u_1\), \(u_2)\) determina em relação ao eixo \(1\). No exemplo, o ponto está situado no círculo unitário, conforme é exigido.
Agora podemos apresentar o função boxmuller para gerar dados de uma normal utilizando o algoritmo de Box-Müller. Essa função utiliza a função polar para gerar dois valores aleatórios, de variáveis aleatórias independentes normais padrão \(Y_1\) e \(Y_2\). A função boxmuller é:
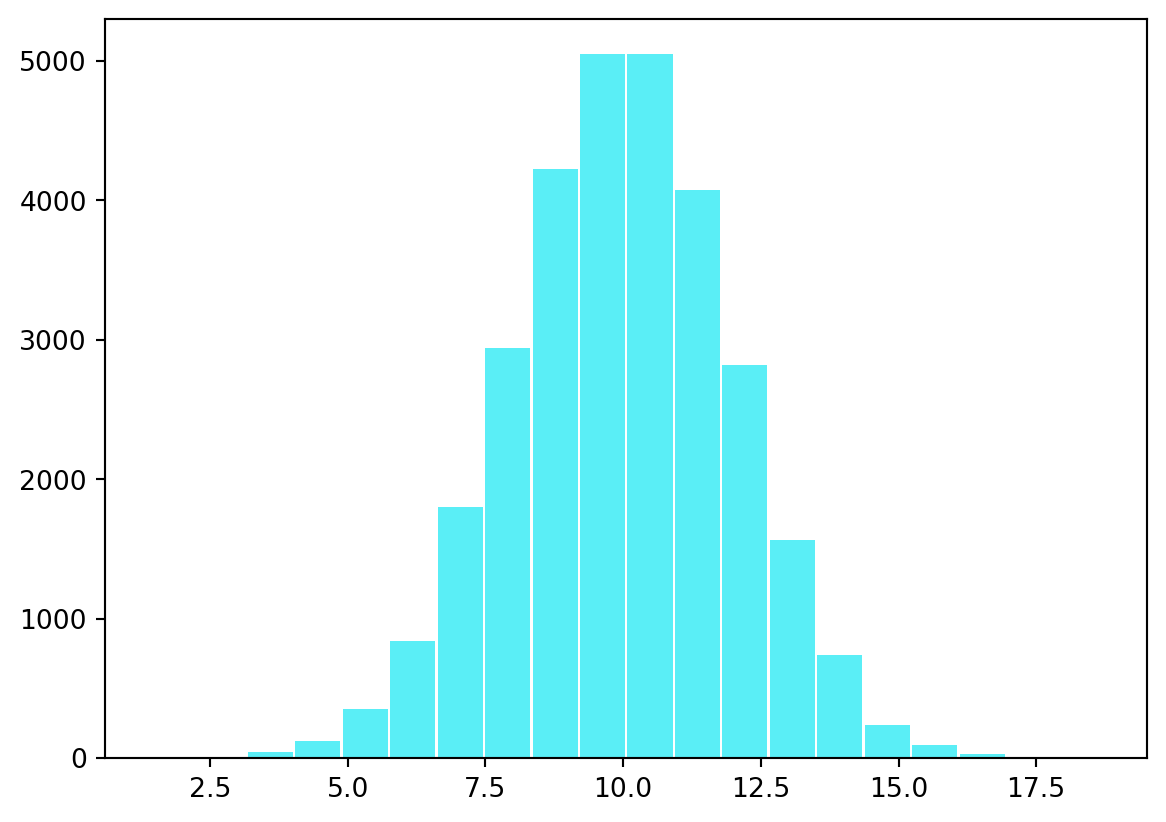
# Função boxmuller retorna uma amostra de tamanho n de# uma distribuição normal com média mu e variância sigma^2# utilizando o método Polar Box-Müllerimport matplotlib.pyplot as pltdef polar(): r2 =-1while r2 <=0or r2 >=1: u = np.random.uniform(-1.0,1.0,2) r2 = u[0]**2+u[1]**2 y = (-2* np.log(r2) / r2)**0.5* u return ydef boxmuller(n, mu =0, sigma =1):if n %2==0: # n é par k = n //2for i inrange(k):if i ==0: x = polar()else: x = np.append(x,polar()) else: # n é ímpar k = n //2if k ==0: x = polar()[0]else:for i inrange(k):if i ==0: x = polar()else: x = np.append(x,polar()) x = np.append(x,polar()[0]) x = x * sigma + mu return xn =30000x = boxmuller(n, 10, 2)graf = plt.hist(x, bins=20, color='#14e8f3',rwidth=0.95,alpha=0.7)plt.show()
Algumas aproximações são apresentadas em Atkinson and Pearce (1976) e serão apenas descritas na sequência. Uma das aproximações faz uso da densidade Tukey-lambda e aproxima a normal igualando os quatro primeiros momentos. Esse algoritmo, além de ser uma aproximação, tem a desvantagem de utilizar a exponenciação que é uma operação lenta. Utilizando essa aproximação podemos obter uma variável normal \(X\) a partir de uma variável uniforme \(U\sim U(0,1)\) por: \[\begin{align*}
X=[U^{0,135}-(1-U)^{0,135}]/{0,1975}.
\end{align*}\]
Outro método é baseado na soma de \(12\) ou mais variáveis uniformes \((U_i\sim U(0,1))\) independentes. Assim, a variável \(X=\sum_i^{12}U_i - 6\) tem distribuição aproximadamente normal com média \(0\) e variância \(1\). Isso ocorre em decorrência do teorema do limite central e em razão de cada uma das \(12\) variáveis uniformes possuírem média \(1/2\) e variância \(1/12\).
Estas duas aproximações tem valor apenas didático e não devem ser recomendadas como uma forma de gerar variáveis normais. Muitas vezes esse fato é ignorado em problemas que requerem elevada precisão e confiabilidade dos resultados obtidos. Quando isso acontece conclusões incorretas ou no mínimo imprecisas podem ser obtidas.
De uma forma geral temos \[X=\dfrac{\displaystyle \sum_{i=1}^{k}U_i - \frac{k}{2}}{\sqrt{\displaystyle\frac{k}{12}}} \sim N(0,1),\] pois \(E(U_i)=(b-a)/2\) e \(V(U_i)=(b-a)^2/12\), em que \(k\) é o número de uniformes que devem ser somadas para cada realização da variável normal. A seguir, implementamos essas duas aproximações para fins de treinamento em criação de funções com o Python.
A primeira é a Tukey-Lambda:
# Aproximação baseada na Tukey-Lambdadef tukeylambda(n, mu =0, sigma =1): x = np.random.uniform(0.0,1.0,n) x = (x**0.135-(1-x)**0.135) /0.1975 x = x * sigma + mureturn xn =1000000x = tukeylambda(n, 10,10)np.mean(x)np.std(x)
np.float64(10.008875154261693)
np.float64(10.015039164203765)
A segunda é a aproximação da soma de k uniformes, usando o teorema do limite central:
# Aproximação baseada na soma de k# uniformes def soma_un(u, k):if k ==12: rn = np.sum(u) -6else: rn = (np.sum(u) - k /2) / (k /12)**0.5return rndef norm_tlc(n, mu =0, sigma =1, k =12): x = []for i inrange(n): u = np.random.uniform(0.0,1.0,k) x. append(soma_un(u, k)) x = np.asarray(x) * sigma + mureturn xn =100000k =12x = norm_tlc(n, 10, 10, k)np.mean(x)np.std(x)
np.float64(10.039050743076714)
np.float64(10.007410815931513)
3.4 Distribuição Binomial
Vamos ilustrar a partir da binomial a geração de realizações de variáveis aleatórias discretas. A distribuição binomial é surpreendentemente importante nas aplicações da estatística. Esta distribuição aparece nas mais variadas situações reais e teóricas. Por exemplo, o teste não-paramétrico do sinal utiliza a distribuição binomial, a ocorrência de animais doentes em uma amostra de tamanho \(n\) pode ser muitas vezes modelada pela distribuição binomial. Inúmeros outros exemplos poderiam ser citados. A distribuição binomial é a primeira distribuição discreta de probabilidade, entre as distribuições já estudadas. A variável aleatória \(X\) com distribuição de probabilidade binomial tem a seguinte função de probabilidade:
\[
P(X=x)= \binom{n}{x} p^x(1-p)^{n-x}, \qquad x=0,1,\cdots, n \quad
\textrm{e} \quad n \ge 1,
\tag{3.12}\] em que os parâmetros \(n\) e \(p\) referem-se, respectivamente, ao tamanho da amostra e a probabilidade de sucesso de se obter um evento favorável em uma amostragem de \(1\) único elemento ao acaso da população. O termo \(\binom{n}{x}\) é o coeficiente binomial definido por: \[\begin{align*}
\binom{n}{x}=\frac{n!}{x!(n-x)!}.
\end{align*}\]
A probabilidade de sucesso \(p\), em amostras de tamanho \(n\) da população, ou seja, em \(n\) ensaios de Bernoulli, deve permanecer constante e os sucessivos ensaios devem ser independentes. O parâmetro \(n\) em geral é determinado pelo pesquisador e deve ser um inteiro maior ou igual a \(1\). Se \(n=1\), então a distribuição binomial se especializa na distribuição Bernoulli. Assim, a distribuição binomial é a repetição de \(n\) ensaios Bernoulli independentes e com probabilidade de sucesso constante. Os seguintes teoremas e lemas são importantes, para a definição de alguns métodos que apareceram na sequência. Estes lemas serão apresentados sem as provas.
Theorem 3.2 (Gênese) Seja \(X\) o número de sucessos em uma sequência de \(n\) ensaios Bernoulli com probabilidade de sucesso \(p\), ou seja, \[X=\sum_{i=1}^{n}I(U_i \le p)\] em que \(U_1\), \(U_2\),\(\cdots\), \(U_n\) são variáveis uniformes \((0,1)\) i.i.d. e \(I(\bullet)\) é uma função indicadora. Então, \(X\) tem distribuição binomial \((n, p)\).
Lemma 3.1 (Soma de binomiais) Se \(X_1\), \(X_2\), \(\cdots\), \(X_k\) são variáveis aleatórias binomiais independentes com \((n_1, p)\), \(\cdots\), \((n_k, p)\), então \(\sum_{i=1}^{k} X_i\) tem distribuição binomial, com parâmetros \((\sum_{i=1}^{k}n_i, p)\).
Lemma 3.2 (Tempo de Espera - Propriedade 1) Sejam \(G_1\), \(G_2\), \(\cdots\) variáveis aleatórias geométricas independentes e, \(X\), o menor inteiro tal que \[\sum_{i=1}^{X+1} G_i>n.\] Assim, \(X\) tem distribuição binomial \((n, p)\).
As variáveis geométricas citadas no lema Lemma 3.2 são definidas a seguir. Se \(G\) tem distribuição geométrica com probabilidade de sucesso constante \(p \in (0,1)\), então, a função de probabilidade é: \[
P(G=g)= p(1-p)^{g-1}, \qquad g=1,2\cdots
\tag{3.13}\]
A geométrica é a distribuição do tempo de espera até a ocorrência do primeiro sucesso no \(g\)-ésimo evento, numa sequência de ensaios Bernoulli independentes. Assim, supõe-se que venham a ocorrer \(g-1\) fracassos, cada um com probabilidade de ocorrência constante \(1-p\), antes da ocorrência de um sucesso no \(g\)-ésimo ensaio, com probabilidade \(p\). Finalmente, o segundo lema do tempo de espera pode ser anunciado por:
Lemma 3.3 (Tempo de Espera - Propriedade 2) Sejam \(E_1\), \(E_2\), \(\cdots\) variáveis aleatórias exponenciais i.i.d., e \(X\) o menor inteiro tal que \[\sum_{i=1}^{X+1} \frac{E_i}{n-i+1}>-ln(1-p).\] Logo, \(X\) tem distribuição binomial \((n, p)\).
As propriedades especiais da distribuição binomial, descritas no teorema e nos lemas, formam a base para dois algoritmos binomiais. Estes dois algoritmos são baseados na propriedade de que uma variável aleatória binomial é á soma de \(n\) variáveis Bernoulli obtidas em ensaios independentes e com probabilidade de sucesso constante \(p\). O algoritmo binomial mais básico baseia-se na geração de \(n\) variáveis independentes \(U(0,1)\) e no cômputo do total das que são menores ou iguais a \(p\). Este algoritmo denominado por Kachitvichyanukul and Schmeiser (1988) de BU é dado por:
Faça \(x=0\) e \(k=0\);
Gere \(u\) de uma \(U(0,1)\) e faça \(k=k+1\);
Se \(u \le p\), então faça \(x=x+1\);
Se \(k<n\) vá para o passo \(2\);
Retorne \(x\) de uma binomial \((n, p)\).
O algoritmo BU tem velocidade proporcional a \(n\) e depende da velocidade do gerador de números aleatórios, mas possui a vantagem de não necessitar de variáveis de setup. O segundo algoritmo atribuído a Devroy 1980 (Devroy 1980) é denominado de BG e é baseado no lema Lemma 3.2. O algoritmo BG pode ser descrito por:
Faça \(y=0\), \(x=0\) e \(c=ln(1-p)\);
Se \(c\) = \(0\), vá para o passo 6;
Gere \(u\) de uma \(U(0,1)\);
\(y=y+\lfloor \ln(u)/c \rfloor+1\), em que \(\lfloor \bullet \rfloor\) denotam a parte inteira do argumento \(\bullet\);
Se \(y \le n\), faça \(x=x+1\) e vá para o passo 3;
Retorne \(x\) de uma binomial \((n, p)\).
O algoritmo utilizado no passo 4 do algoritmo BG é baseado em truncar uma variável exponencial \(G=\lfloor \ln(U)/c \rfloor+1 \sim G(p)\) para gerar uma variável geométrica, conforme descrição feita por Devroy (1986). O tempo de execução desse algoritmo é proporcional a \(np\), o que representa uma considerável melhoria da performance. Assim, \(p>0,5\), pode-se melhorar o tempo de execução de BG explorando a propriedade de que se \(X\) é binomial com parâmetro \(n\) e \(p\), então \(n-X\) é binomial com parâmetros \(n\) e \(1-p\). Especificamente o que devemos fazer é substituir \(p\) pelo \(\min(p,1-p)\) e retornar \(x\) se \(p \le \frac{1}{2}\) ou retornar \(n-x\), caso contrário. A velocidade, então, é proporcional a \(n\) vezes o valor \(\min(p,1-p)\). A desvantagem desse procedimento é que são necessárias várias chamadas do gerador de realizações de variáveis aleatórias uniformes, até que um sucesso seja obtido e o valor \(x\) seja retornado. Uma alternativa a esse problema pode ser conseguida se utilizarmos um gerador baseado na inversão da função de distribuição binomial.
Como já havíamos comentado em outras oportunidades o método da inversão é o método básico para convertermos uma variável uniforme \(U\) em uma variável aleatória \(X\), invertendo a função de distribuição. Para uma variável aleatória contínua, temos o seguinte procedimento:
Gerar um número uniforme \(u\)
Retornar \(x=F^{-1}(u)\)
O procedimento análogo para o caso discreto requer a busca do valor \(x\), tal que: \[\begin{align*}
F(x-1)=\sum_{i<x}P(X=i)<u\le \sum_{i\le x}P(X=i)=F(x).
\end{align*}\]
A maneira mais simples de obtermos uma solução no caso discreto é realizarmos uma busca sequencial a partir da origem. Para o caso binomial, este algoritmo da inversão, denominado de BINV, pode ser implementado se utilizarmos a fórmula recursiva:
\[
\left\{\begin{array}{rl}
P(X=0)&= (1-p)^n \\
\\
P(X=x)&=P(X=x-1)\frac{n-x+1}{x}\frac{p}{1-p}
\end{array}\right.
\tag{3.14}\] para \(x=1,2,\cdots,n\) da seguinte forma:
Gere \(u\) de uma \(U(0,1)\) e faça \(x=0\) e \(F=f\);
Se \(F >= u\), então vá para o passo 5;
Faça \(x = x + 1\), \(f=f\left(\dfrac{g}{x}-r\right)\), \(F=F + f\) e vá para o passo 3;
Se \(p \le \frac{1}{2}\), então retorne \(x\) de uma binomial \((n, p)\), senão retorne \(n-x\) de uma binomial \((n, p)\).
A velocidade deste algoritmo é proporcional a \(n\) vezes o valor \(\min(p,\,1-p)\). A vantagem desse algoritmo é que apenas uma variável aleatória uniforme é gerada para cada variável binomial requerida. Um ponto importante é o tempo consumido para gerar \(qq^n\) é substancial e dois problemas potenciais podem ser destacados. O primeiro é a possibilidade de no cálculo de \(f=qq^n\), quando \(n\) é muito grande e, o segundo, é a possibilidade do cálculo recursivo de \(f\) ser uma fonte de erros de arredondamento, que se acumulam e que se tornam sérios na medida que \(n\) aumenta (Kachitvichyanukul and Schmeiser 1988). Devroy (1986) menciona que o algoritmo do tempo de espera BG baseado no lema Lemma 3.2 deve ser usado no lugar de BINV para evitarmos esses fatos. Por outro lado, Kachitvichyanukul and Schmeiser (1988) mencionam que basta implementar o algoritmo em precisão dupla que esses problemas são evitados.
# Exemplificação de algoritmos para gerar realizações de# variáveis aleatórias binomiais binom(n, p).# Os algoritmos BU, BG e BINV foram implementados# Exemplificação de algoritmos para gerar realizações de# variáveis aleatórias binomiais binom(n, p).# Os algoritmos BU, BG e BINV foram implementadosimport numpy as npdef bu(n, p): x =0 k =0while k < n: u = np.random.uniform(0.0,1.0,1) k = k +1if u <= p: x +=1return(x) def bg(n, p):if p >0.5: pp =1- pelse: pp = p y =0 x =0 c = np.log(1- pp)if c <0:while y <= n: u = np.random.uniform(0.0,1.0,1) y += np.trunc(np.log(u) /c) +1if y <= n: x +=1if p >0.5: x = n - xreturn xdef binv(n, p):if p >0.5: pp =1- pelse: pp = p q =1- pp f = q**n r = pp / q g = r * (n +1) u = np.random.uniform(0.0,1.0,1) x =0 Fx = fwhile Fx < u: x +=1 f *= (g / x - r) Fx += fif p >0.5: x = n - xreturn x # gerador de uma amostra binomial n, p# recebe uma das três funções implementas# como argumento, size e prob# são os parâmetros da binomial e n é o# tamanho da amostra ser gerada# recebe bg por defaultdef rbinom(n, size, prob, func = bg): x = []for i inrange(n): x.append(func(size, prob))return x# Exemploprob =0.5size =3bu(size, prob)bg(size, prob)binv(size, prob)n =10000# sample sizex = rbinom(n, size, prob, bg) # pode trocar bg por binv ou bugraf = plt.hist(x,bins=size+1,color='#14e8f3',rwidth=0.95,alpha=0.7)
3
3
3
Procedimentos de geração de números aleatórios poderiam ser apresentados para muitas outras distribuições de probabilidades. Felizmente no python não temos este tipo de preocupação, pois estas rotinas já existem e estão implementadas em linguagem não interpretada. Inclusive para os modelos considerados temos rotinas prontas. Veremos uma boa parte delas na próxima seção.
3.5 Rotinas Python para Geração de Realizações de Variáveis Aleatórias
Nesta seção, veremos alguns dos principais comandos Python para acessarmos os processos de geração de realizações de variáveis aleatórias de diferentes modelos probabilísticos. Os modelos probabilísticos contemplados pelo R estão apresentados na Tabela Table 3.1.
Table 3.1: Distribuições de probabilidades, nome Python (np.random.col2nome) e parâmetros (argumentos da função) dos principais modelos probabilístico, sendo size o tamanho da amostra.
Distribuição
Nome numpy
Parâmetros
beta
beta(a, b, size=None)
a, b, size
binomial
binomial(n, p, size=None)
n, p,size
Cauchy Padrão
standard_cauchy(size=None)
size
qui-quadrado
chisquare(df, size=None)
df, size
exponencial
exponential(scale=1.0, size=None)
scale (1/lambda), size
F
f(dfnum, dfden, size=None)
dfnum, dfden, size
gama
gamma(shape, scale=1.0, size=None)
shape, scale (1/beta), size
geométrica
geometric(p, size=None)
p, size
hipergeométrica
hypergeometric(ngood, nbad, nsample, size=None)
ngood, nbad, nsample, size
log-normal
lognormal(mean=0.0, sigma=1.0, size=None)
mean, sigma, size
logística
logistic(loc=0.0, scale=1.0, size=None)
loc, scale, size
binomial negativa
negative_binomial(n, p, size=None)
n, p, size
normal
normal(loc=0.0, scale=1.0, size=None)
loc, scale, size
Poisson
poisson(lam=1.0, size=None)
lam, size
t de Student
standard_t(df, size=None)
df, size
uniform
uniform(low=0.0, high=1.0, size=None)
low, high, size
Weibull
weibull(a, size=None)
a, size
No Python, a biblioteca scipy.stats nos permite realizarmos os cálculos da função de probabilidade (caso discreto) com o comando, por exemplo, para a binomial, de sp.stats.binom.pmf(x, n,p). Neste caso, o scipy foi importado com sp e pmf é acrônimo de probability mass function, do inglês. Para o caso contínuo, usamos pdf. Para a função de distribuição, usamos cdf, sejam as variáveis contínuas ou discretas. Para a inversa da função de distribuição, usamos ppf, percent point function. Neste caso o primeiro argumento é o valor da probabilidade acumulada. No caso particular deste capítulo temos interesse na geração de realizações de variáveis aleatórias. Existem ainda modelos probabilísticos não centrais, para os quais devemos utilizar o parâmetro de não-centralidade (ncp). Para mais detalhes, visite a página do scipy.stats clicando aqui.
O uso destas funções para gerarmos números aleatórios é bastante simples. Se, por exemplo, quisermos gerar dados de uma distribuição beta com parâmetros \(\alpha=1\) e \(\beta=2\), podemos utilizar o programa ilustrativo apresentado na sequência. Podemos utilizar funções semelhantes a função beta, de acordo com a descrição feita na Tabela Table 3.1, para gerarmos \(n\) dados de qualquer outra função densidade ou função de probabilidade. Este procedimento é mais eficiente do que utilizarmos nossas próprias funções, pois estas funções foram implementadas em geral em \(C\). Se para algum modelo particular desejarmos utilizar nossas próprias funções e se iremos chamá-las milhares ou milhões de vezes é conveniente que implementemos em C e as associemos ao Python. A forma de associarmos as rotinas escritas em C ao Python foge do escopo deste material e por isso não explicaremos como fazê-lo.
Seja \(f(x)=3x^2\) uma função densidade de uma variável aleatória contínua \(X\) com domínio definido no intervalo \([0; 1]\). Aplicar o método da inversão e descrever um algoritmo para gerar realizações de variáveis aleatórias dessa densidade. Implementar em R e gerar uma amostra de tamanho \(n=1.000\). Estimar os quantis \(1\%\), \(5\%\), \(10\%\), \(50\%\), \(90\%\), \(95\%\) e \(99\%\). Confrontar com os quantis teóricos.
Os dados a seguir referem-se ao tempo de vida, em dias, de \(n=40\) insetos. Considerando que a distribuição do tempo de vida é a exponencial e que o parâmetro \(\lambda\) pode ser estimado pelo estimador de máxima verossimilhança \(\hat{\lambda}=1/\bar{X}\), em que \(\bar{X}=\sum_{i=1}^{n}X_i/n\), obter o intervalo de \(95\%\) de confiança utilizando o seguinte procedimento: i) gerar uma amostra da exponencial de tamanho \(n=40\), utilizando o algoritmo rexpon, considerando o parâmetro igual a estimativa obtida; ii) determinar a estimativa da média \(\mu=1/\lambda\) por \(\bar{X}\) nesta amostra simulada de tamanho \(n=40\); iii) repetir \(1.000\) vezes os passos (i) e (ii) e armazenar os valores obtidos; iv) ordenar as estimativas e tomar os quantis \(2,5\%\) e \(97,5\%\). Os valores obtidos são o intervalo de confiança almejado, considerando como verdadeira a densidade exponencial para modelar o tempo de vida dos insetos. Este procedimento é denominado de bootstrap paramétrico. Os dados em dias do tempo de vida dos insetos são:
8,521
4,187
2,516
1,913
8,780
5,912
0,761
12,037
2,604
1,689
5,626
6,361
5,068
3,031
1,128
1,385
12,578
2,029
0,595
0,445
3,601
7,829
1,383
1,934
0,864
8,514
4,977
0,576
1,503
0,475
1,041
0,301
1,781
2,564
5,359
2,307
1,530
8,105
3,151
8,628
Repetir esse processo, gerando \(100.000\) amostras de tamanho \(n=40\). Compare os resultados e verifique se o custo adicional de ter aumentado o número de simulações compensou a possível maior precisão obtida.
Gerar uma amostra de \(n=5.000\) realizações de variáveis normais padrão utilizando as aproximações: \(X=[U^{0,135}\)\(-(1-U)^{0,135}]/\)\({0,1975}\) e da soma de \(12\) ou mais variáveis uniformes \((U_i\sim U(0,1))\) independentes, dada por \(X=\sum_i^{12}U_i - 6\). Confrontar os quantis \(1\%\), \(5\%\), \(10\%\), \(50\%\), \(90\%\), \(95\%\) e \(99\%\) esperados da distribuição normal com os estimados dessa distribuição. Gerar também uma amostra de mesmo tamanho utilizando o algoritmo Polar-Box-Müller. Estimar os mesmos quantis anteriores nesta amostra e comparar com os resultados anteriores.
Se os dados do exercício 2 pudessem ser atribuídos a uma amostra aleatória da distribuição log-normal, então estimar os parâmetros da log-normal e utilizar o mesmo procedimento descrito naquele exercício, substituindo apenas a distribuição exponencial pela log-normal para estimar por intervalo a média populacional. Para estimar os parâmetros da log-normal utilizar o seguinte procedimento: a) transformar os dados originais, utilizando \(X^*_{i}=\ln(X_i)\); b) determinar a média e o desvio padrão amostral dos dados transformados - estas estimativas são as estimativas de \(\mu\) e \(\sigma\). Utilizar estas estimativas para gerar amostras log-lognormais. Realizar os mesmos procedimentos descritos para exponencial, confrontar os resultados e discutir a respeito da dificuldade de se tomar uma decisão da escolha da distribuição populacional no processo de inferência. Como em situações reais nunca se sabe de qual distribuição os dados são provenientes com precisão, então você teria alguma ideia de como fazer para determinar qual a distribuição que melhor modela os dados do tempo de vida dos insetos? Justificar sua resposta adequadamente com os procedimentos numéricos escolhidos.
Fazer reamostragens com reposição a partir da amostra do exercício 2 e estimar o intervalo de \(95\%\) para a média populacional, seguindo os passos descritos a seguir e utilizar um gerador de números uniformes para determinar quais elementos amostrais devem ser selecionados: i) reamostrar com reposição os \(n=40\) elementos da amostra original e compor uma nova amostra por: \(X^*_i\); ii) calcular a média desta nova amostra por \(\bar{X}^*=\sum_{i=1}^{n}X_i^*/n\); iii) armazenar este valor e repetir os passos (i) e (ii) \(B-1\) vezes; iv) agrupar os valores com o valor da amostra original; e v) ordenar os valores obtidos e determinar os quantis \(2,5\%\) e \(97,5\%\) desse conjunto de \(B\) valores. Escolher \(B=1.000\) e \(B=100.000\) e confrontar os resultados obtidos com os obtidos nos exercícios anteriores para a distribuição exponencial e log-normal. Os resultados que estiverem mais próximos deste resultado devem fornecer um indicativo da escolha da distribuição mais apropriada para modelar o tempo de vida de insetos. Este procedimento sugerido neste exercício é o bootstrap não-paramétrico. A sua grande vantagem é não precisar fazer suposição a respeito da distribuição dos dados amostrais.
Uma importante relação para obtermos intervalos de confiança para a média de uma distribuição exponencial, \(f(x)\)\(=\)\(\lambda e^{-\lambda x}\), refere-se ao fato de que a soma de \(n\) variáveis exponenciais com parâmetro \(\lambda\) é igual a uma gama \(f(y)\)\(=\)\(\frac{1}{\lambda\Gamma(\alpha)}\left(y/\beta\right)^{\alpha-1} e^{-\frac{y}{\beta}}\) com parâmetros \(\alpha=n\) e \(\beta=1/\lambda\). Assim, assumir que os dados do exercício 2 têm distribuição exponencial com parâmetro \(\lambda\) estimado pelo recíproco da média amostral, ou seja, \(\hat{\beta}\)\(=\)\(1/\bar{X}\). Considerando que a variável \(X\) tem distribuição gama padrão com parâmetro \(\alpha=n\), então obtenha \(Y\)\(=\)\(\hat{\beta} X\)\(=\)\(X/\hat{\lambda}\). Neste caso \(Y|\hat{\beta}\) tem distribuição da soma de \(n\) variáveis exponenciais, ou seja, distribuição gama com parâmetros \(\alpha\)\(=\)\(n\) e \(\beta\)\(=\)\(\hat{\beta}\). Como queremos a distribuição da média, devemos obter a transformação \(\bar{Y}=Y/n\). Gerar amostras de tamanho \(n=1.000\) e \(n=100.000\) e estimar os quantis \(2,5\%\) e \(97,5\%\) da distribuição de \(\bar{Y}\), em cada uma delas. Confrontar os intervalos de confiança, dessa forma obtidos, com os do exercício 2. Quais são as suas conclusões? Qual é a vantagem de utilizar a distribuição gama?
Duas amostras binomiais foram realizadas em duas \((1\) e \(2)\) diferentes populações. Os resultados do número de sucesso foram \(y_1=2\) e \(y_2=3\) em amostras de tamanho \(n_1=12\) e \(n_2=14\), respectivamente, de ambas as populações. Estimar os parâmetros \(p_1\) e \(p_2\) das duas populações por: \(\hat{p_1}=y_1/n_1\) e \(\hat{p_2}=y_2/n_2\). Para testarmos a hipótese \(H_0: p_1=p_2\) ou \(H_0:\)\(p_1-p_2\)\(=\)\(0\), podemos utilizar o seguinte algoritmo bootstrap paramétrico: a) utilizar \(\hat{p_1}\) e \(\hat{p_2}\) para gerarmos amostras de tamanho \(n_1\) e \(n_2\) de ambas as populações; b) estimar \(\hat{p_{1j}}=y_{1j}/n_1\) e \(\hat{p_{2j}}=y_{2j}/n_2\) na j-ésima repetição desse processo; c) calcular \(d_j=\hat{p_{1j}}-\hat{p_{2j}}\); d) repetir os passos de (a) a (c) \(B-1\) vezes; e) unir com o valor da amostra original; f) ordenar os valores e obter os quantis \(2,5\%\) e \(97,5\%\) da distribuição bootstrap de \(d_j\); e g) se o valor hipotético \(0\) estiver contido nesse intervalo, não rejeitar \(H_0\), caso contrário, rejeitar a hipótese de igualdade das proporções binomiais das duas populações.
Atkinson, A. C., and M. C. Pearce. 1976. “The Computer Generation of Beta, Gamma and Normal Random Variable.”Journal of the Royal Statistical Society, Series a 139 (4): 431–61.
Devroy, L. 1980. “Generating the Maximum of Independent Identically Distributed Random Variables.”Computers and Mathematics with Applications 6: 305–15.
———. 1986. Non-Uniform Random Variate Generation. new york: springer-verlag.
Johnson, R. A., and D. W. Wichern. 1998. Applied Multivariate Statistical Analysis. 4th ed. New Jersey: Prentice Hall.
Kachitvichyanukul, V., and B. W. Schmeiser. 1988. “Binomial Random Variate Generation.”Communications of the ACM 31 (2): 216–22.
Marsaglia, G., and T. A. Bray. 1964. “A Convenient Method for Generating Normal Variables.”Siam Review 6 (3): 260–64.
Press, W. H., B. P. Flannery, S. A. Teukolsky, and W. T. Vetterling. 1992. Numerical Recipes in Fortran: The Art of Scientific Computing. Cambridge: Cambridge University Press.