Algoritmos para a obtenção de probabilidades foram alvos de pesquisas de muitas décadas e ainda continuam sendo. A importância de se ter algoritmos que sejam rápidos e precisos é indescritível. A maior dificuldade é que a maioria dos modelos probabilísticos não possui função de distribuição explicitamente conhecida. Assim, métodos numéricos sofisticados são exigidos para calcularmos probabilidades. Um outro aspecto é a necessidade de invertermos as funções de distribuição para obter quantis da variável aleatória para uma probabilidade acumulada conhecida. Nos testes de hipóteses e nos processos de estimação por intervalo e por região quase sempre utilizamos estes algoritmos indiretamente sem nos darmos conta disso.
Neste capítulo vamos introduzir estes conceitos e apresentar algumas ideias básicas de métodos gerais para realizar as quadraturas necessárias. Métodos numéricos particulares serão abordados para alguns poucos modelos. Também abordaremos separadamente os casos discreto e contínuo. Para finalizarmos apresentaremos as principais funções pré-existentes do Python para uma série de modelos probabilísticos.
6.1 Introdução
Não temos muitas preocupações com a obtenção de probabilidades e quantis, quando utilizamos o Python, pois a maioria dos modelos probabilísticos e das funções especiais já está implementada. Nosso objetivo está além deste fato, pois nossa intenção é buscar os conhecimentos necessários para ir adiante e para entendermos como determinada função opera e quais são suas potencialidades e limitações.
Vamos iniciar nossa discussão com a distribuição exponencial para chamarmos a atenção para a principal dificuldade existente neste processo. Assim, escolhemos este modelo justamente por ele não apresentar tais dificuldades. Considerando uma variável aleatória \(X\) com distribuição exponencial com parâmetro \(\lambda\), temos a função densidade \[
f(x) = \lambda e^{-\lambda x}, \quad x>0
\tag{6.1}\] e a função de distribuição \[
F(x)=1-e^{-\lambda x}.
\tag{6.2}\]
Para este modelo probabilístico podemos calcular probabilidades utilizando a função de distribuição (Equation 6.2) e obter quantis com a função de distribuição inversa que é dada por: \[
q=F^{-1}(p)=\dfrac{-\ln(1-p)}{\lambda}.
\tag{6.3}\]
Implementamos, em Python, as funções densidade, de distribuição e inversa da distribuição e as denominamos dexp, pexp e qexp, respectivamente. Estas funções são:
fdp de valores negativos: [0.005 0. ]
cdf de valores negativos: [0.94999999 0. ]
NaN produzidos!
icdf de valores impróprios: [ nan 29.95732274 nan]
fdp: [0.005]
cdf: [0.94999999]
icdf: [29.95732274]
Estas três funções foram facilmente implementadas, pois conseguimos explicitamente obter a função de distribuição e sua inversa. Se por outro lado tivéssemos o modelo normal
\[
f(x) = \dfrac{1}{\sqrt{2\pi\sigma^2}} \exp\left\{-\dfrac{(x-\mu)^2}{2\sigma^2}\right\}
\tag{6.4}\] não poderíamos obter explicitamente a função de distribuição e muito menos a função inversa da função de distribuição de probabilidade. Como para a grande maioria dos modelos probabilísticos encontramos os mesmos problemas, necessitamos de métodos numéricos para obter estas funções. Por essa razão iremos apresentar alguns detalhes neste capítulo sobre alguns métodos gerais e específicos de alguns modelos. No caso discreto podemos utilizar algoritmos sequenciais, porém como boa parte dos modelos probabilísticos possuem relação exata com modelos contínuos, encontramos os mesmos problemas.
Uma outra preocupação que devemos ter é em relação a possíveis entradas incorretas do usuário nos argumentos das funções. Não tivemos muitas preocupações até o momento com possíveis erros em função de chamadas de nossas funções com argumentos incorretos. Para ilustrarmos, vamos considerar somente a função densidade de probabilidade da exponencial. Neste caso, se \(\lambda>0\), e os valores de \(x\) positivos ou nulos, não termos nenhum problema. Se por outro lado, os valores de \(x\) forem negativos, então o valor da densidade deve ser zero. Este tipo de preocupação existiu na implementação da função dexp anterior. Entretanto, podemos ter valores do parâmetro \(\lambda\) nulo ou negativo incorretamente na chamada da função, o que não é válido e nenhuma proteção foi feita. Assim, é prudente que alguns problemas sejam antevistos e resultados coerentes sejam retornados. Neste caso deve-se retornar o resultado nan, pois a função densidade não é válida nestas condições. Além disso, o argumento lamb da função é considerado um escalar, mas o argumento x pode ser um vetor. Podemos também tratar este caso, considerando tratar ambos argumentos como vetores, mesmo que não mudemos o valor escalar do argumento lamb padrão e fazer um ajuste nas dimensões dos mesmos, caso eles tenham tamanhos diferentes. O programa a seguir ilustra isso e utiliza o np.resize para realizar este ajuste.
import numpy as npdef dexp(x, lamb=1):# Converter para arrays e garantir que são floats x_arr = np.array(x, ndmin=1, dtype=float) lamb_arr = np.array(lamb, ndmin=1, dtype=float)# Expandir para terem o mesmo tamanho size =max(len(x_arr), len(lamb_arr)) x_expanded = np.resize(x_arr, size) lamb_expanded = np.resize(lamb_arr, size)# Inicializar resultado com NaN para lidar com casos inválidos result = np.full(size, np.nan, dtype=float)# Máscara para valores válidos de lambda (positivos e não zero) valid_lambda = lamb_expanded >0# Máscara para valores válidos de x (não negativos) valid_x = x_expanded >=0# Máscara combinada: x >= 0 E lambda > 0 valid_mask = valid_x & valid_lambda# Calcular a densidade apenas para casos válidos result[valid_mask] = (lamb_expanded[valid_mask]* np.exp(-lamb_expanded[valid_mask]*x_expanded[valid_mask]))# Para x < 0 COM lambda válido: resultado é 0# Para x < 0 COM lambda inválido: mantém NaN (já inicializado) result[(x_expanded <0) & valid_lambda] =0.0# Retornar formato apropriadoif np.isscalar(x) and np.isscalar(lamb):returnfloat(result[0])else:return result# Testesprint("=== Testes da função dexp ===")# Caso 1: lambda positivo (normal)print("\n1. Lambda positivo:")print(f"dexp(1, 1) = {dexp(1, 1):.4f}")# Caso 2: lambda zeroprint("\n2. Lambda zero:")print(f"dexp(1, 0) = {dexp(1, 0)}")# Caso 3: lambda negativoprint("\n3. Lambda negativo:")print(f"dexp(1, -1) = {dexp(1, -1)}")# Caso 4: mistura de lambdas válidos e inválidosprint("\n4. Mistura de lambdas:")x = [1, 2, 3]lambdas = [0.5, 0, -1]result = dexp(x, lambdas)print(f"x = {x}")print(f"lambdas = {lambdas}")print(f"resultado = {result}")# Caso 5: x negativo (sempre retorna 0, mesmo com lambda inválido)print("\n5. x negativo:")print(f"dexp(-1, 0) = {dexp(-1, 0)}")print(f"dexp(-1, -1) = {dexp(-1, -1)}")# Caso 6: vetores com reciclagemprint("\n6. Reciclagem com lambda inválido:")x = [1, 2, -3, 4]lamb = [0.5, -0.5]result = dexp(x, lamb)print(f"x = {x}")print(f"lamb = {lamb}")print(f"resultado = {result}")# Caso 7: verificação de cálculo corretoprint("\n7. Verificação de valores esperados:")test_cases = [ (0, 1, 1.0), # f(0) = lambda (1, 1, np.exp(-1)), # f(1) = e^-1 (2, 0.5, 0.5* np.exp(-1)) # f(2) = 0.5 * e^-1 ] for x_val, lamb_val, expected in test_cases: result = dexp(x_val, lamb_val)print(f"dexp({x_val}, {lamb_val}) = {result:.4f} (esperado: {expected:.4f})")
=== Testes da função dexp ===
1. Lambda positivo:
dexp(1, 1) = 0.3679
2. Lambda zero:
dexp(1, 0) = nan
3. Lambda negativo:
dexp(1, -1) = nan
4. Mistura de lambdas:
x = [1, 2, 3]
lambdas = [0.5, 0, -1]
resultado = [0.30326533 nan nan]
5. x negativo:
dexp(-1, 0) = nan
dexp(-1, -1) = nan
6. Reciclagem com lambda inválido:
x = [1, 2, -3, 4]
lamb = [0.5, -0.5]
resultado = [0.30326533 nan 0. nan]
7. Verificação de valores esperados:
dexp(0, 1) = 1.0000 (esperado: 1.0000)
dexp(1, 1) = 0.3679 (esperado: 0.3679)
dexp(2, 0.5) = 0.1839 (esperado: 0.1839)
Neste caso, a função faz um redimensionamento automático dos vetores por repetição para equalizar seus tamanhos antes do cálculo elemento a elemento. Isso ocorre com o uso do np.resize, após o tamanho máximo em relação ao tamanho de ambos os vetores ser obtido. Se os tamanhos são diferentes, faz-se uma reciclagem incompleta do vetor menor através de repetição cíclica, truncando o padrão quando atinge o tamanho do vetor maior, sem completar o último ciclo. Isso quer dizer que se faz uma reciclagem cíclica do vetor menor, interrompendo a repetição quando atinge o tamanho exato do vetor maior, mesmo que isso signifique deixar o último ciclo incompleto. Depois de ajustados os tamanhos dos vetores, cria-se um vetor result para os resultados com nan. Assim, se tiver valores inválidos, obtém-se uma máscara booleana combinada de valores de x não negativos e de lamb positivos. Cálcula-se a densidade apenas onde estas duas condições ocorrem simultaneamente e substitui os nan de result pelos valores da densidade. O problema é que se o x for negativo e o lamb for positivo, o valor da densidade deve ser zero e ela não é computada com o uso da máscara anterior. Mas se x for negativo e lambda inválido, mantém os nan enteriormente definidos em result. Por definição, a função densidade de probabilidade existe para todos os reais, desde que os parâmetros dos modelos estejam corretamente definidos. O programa faz um ajuste específico final para o caso onde x é negativo mas lamb é positivo, com o comando result[(x_expanded < 0) & valid_lambda] = 0.0 (veja o caso 6).
6.2 Modelos Probabilísticos Discretos
Vamos apresentar algoritmos para obtenção da função de probabilidade, função de distribuição de probabilidade e sua inversa para os modelos discretos que julgamos mais importantes, os modelos binomial e Poisson. Vamos iniciar nossa discussão pelo modelo binomial. Considerando uma variável aleatória \(X\) com distribuição binomial, então a sua função de probabilidade é dada por:
\[
P(X=x) = \binom{n}{x} p^x (1-p)^{(n-x)}
\tag{6.5}\] em que \(n\) é o tamanho da amostra ou números de ensaios de Bernoulli independentes com probabilidade de sucesso \(p\) e \(x\) é o número de sucessos, que pertence ao conjunto finito \(0\), \(1\), \(\cdots\), \(n\). A função de distribuição de probabilidade é dada por:
Vimos no capítulo 3, equação (Equation 3.14) que podemos obter as probabilidades acumuladas de forma recursiva. Sendo \(P(X=0)= (1-p)^n\), obtemos as probabilidades para os demais valores de \(X\), ou seja, para \(x=1\), \(\cdots\), \(n\) de forma recursiva utilizando a relação \(P(X=x)=P(X=x-1)[(n-x+1)/x] [p/(1-p)]\). Podemos sintetizar da seguinte forma: \[P(X=x)=P(X=x-1) \left(\dfrac{g}{x} - r\right),\] em que \(r=p/(1-p)\) e \(g=r(n+1)\), para \(x=2\), \(3\), \(\cdots\), \(n\).
Este mesmo algoritmo apropriadamente modificado é utilizado para obtermos as probabilidades acumuladas e a inversa da função de distribuição. Se os valores de \(n\) e de \(p\) forem grandes, este algoritmo pode ser ineficiente. Para o caso do parâmetro \(p\) ser grande (próximo de um) podemos utilizar a propriedade da binomial dada por: se \(X \sim\)\(Bin(n, p)\), então \(Y=n-X \sim\)\(Bin(n, 1-p)\). Assim, podemos, por exemplo, obter \(P(X=x)\) de forma equivalente por \(P(Y=n-x)\) e \(P(X\le x) = P(Y\ge n-x)\), que pode ser reescrito por \(F_X(x)= 1-F_Y(n-x-1)\), exceto para \(x=n\), em que \(F_X(x)=1\). Desta forma trocamos de variável para realizar o cálculo e retornamos o valor correspondente a do evento original.
# função de probabilidade e distribuição # da binomial(n, p)def dpbinom(x, n, p =0.5):if p >0.5: pp =1- p xx = n - xelse: pp = p qq =1- ppif (xx <0or xx > n): f =0if xx <0: cdf =1else: cdf =0return {'pdf': f,'cdf': cdf} else: f = qq**n r = pp / qq g = r * (n +1) cdf = f u =0while(u < xx): u +=1 f *= (g / u - r) cdf += fif p >0.5: cdf =1- cdf + f # pois 1-F(n-x) e não 1-F(n-x-1) foi calculadoreturn {'pdf': f,'cdf': cdf} # inversa da função distribuição # binomial(n, p)def qbinom(prob, n, p):if prob <0or prob >1:returnfloat("nan")if prob ==1:return n if prob ==0:return0 q =1- p f = q**n r = p / q g = r * (n +1) x =0 cdf = fwhile (prob - cdf) >=1.e-14: x +=1 f *= (g / x - r) cdf += freturn x # Exemplo de usop =0.5713131x =5# retire a tolerância, qbinom falhan =20res = dpbinom(x, n, p)for keys,values in res.items():print(keys)print(values)prob = res['cdf']print('inversa CDF',qbinom(prob, n, p))
pdf
0.0028636362867051975
cdf
0.0036697111708624904
inversa CDF 5
Se usarmos a propriedade de que se \(X\) é binomial com parâmetros \(n\) e \(p\), então \(n-X\) também é binomial com parâmetros \(n\) e \(1-p\). Como o algoritmo é mais eficiente quando \(p<0,5\), pois \(q\)\(=\)\(1-p\) está mais próximo de \(1\) e a velocidade de execução do algoritmo é proporcional a \(np\). Assim, se ganha em tempo de processamento e precisão, se \(p>0,5\) e nós realizarmos a troca para \(n-X\). O script a seguir apresenta esta alteração na função qbinom:
# inversa da função distribuição # binomial(n, p), com troca se p > 0.5def qqbinom(prob, n, p):if prob <=0or prob >1:returnfloat("nan")if prob ==1:return n if p >0.5: pp =1- p probq =1- probelse: pp = p probq = prob qq =1- pp f = qq**n r = pp / qq g = r * (n +1) x =0 cdf = fwhile ((probq - cdf) >=1.e-11): x +=1 f *= (g / x - r) cdf += fif p >0.5:if (probq - cdf) <=1.e-11: x = n - x -1else: x = n - xreturn x # Exemplo de usop =0.5713131x =5# retire a tolerância, qbinom falhan =20res = dpbinom(x, n, p)print(res)prob = res['cdf']print('inversa CDF',qqbinom(prob, n, p))
A função de distribuição binomial possui uma relação exata com a função distribuição beta. Se tivermos algoritmos para obter a beta incompleta podemos utilizar esta relação para obter probabilidades da distribuição binomial. A função de distribuição binomial, \(F(x)\), se relaciona com a função beta incompleta, \(Ip(\alpha,\beta)\), da seguinte forma:
\[
F(x;n,p) = \left\{ \begin{array}{ll}
1 - I_p(x+1,n-x), & \textrm{ se } 0\le x < n \\
1, & \textrm{ se } x = n.
\end{array} \right.
\tag{6.6}\]
Desta forma podemos antever a importância de conhecermos algoritmos de integração numérica das distribuições contínuas. Isso fica mais evidente quando percebemos que para grandes valores de \(n\) os algoritmos recursivos são ineficientes e podem se tornar imprecisos. Na seção Section 6.3 apresentaremos alguns métodos gerais de integração para funções contínuas. No script seguinte utilizamos a relação (Equation 6.6) para a obtenção da função de distribuição da binomial.
# função de probabilidade e distribuição da # binomial(n, p) a partir da relação com a # função beta incompleta - cdf da betafrom scipy.stats import betaimport scipy.stats as spsdef pbinombeta(x, n, p =0.5):if p <=0or p >=1:print('p deve estar no intervalo (0, 1)')returnif (x < n): a = x +1 b = n - x cdf =1- beta.cdf(p, a, b)else: cdf =1return cdf# Exemplop =0.5713131n =20x =3pbinombeta(x, n, p)sps.binom.cdf(x, n, p)
np.float64(0.00013459360572398715)
np.float64(0.00013459360572400553)
A distribuição Poisson é a segunda que consideraremos. Existe relação da função de distribuição da Poisson com a gama incompleta. Se uma variável aleatória discreta \(X\) com valores \(x=0\), \(1\), \(2\), \(3\), \(\cdots\) possui distribuição Poisson com parâmetro \(\lambda\), então podemos definir a função de probabilidade por:
Podemos obter probabilidades desta distribuição utilizando a relação da gama incompleta com a função de distribuição Poisson \[
F(x|\lambda)=1-I_{\lambda}(\alpha=x+1), \qquad x=0, 1, 2, \cdots.
\tag{6.8}\] sendo \[\begin{align*}
I_{x}(\alpha)=\dfrac{1}{\Gamma(\alpha)}\int_0^x e^{-t}t^{\alpha-1}dt,
\end{align*}\] a função gama incompleta, para valores de \(x\ge 0\). O script para isso é
# função de probabilidade e distribuição da # Poisson(lamb) usando a relação com a função# gama incompleta - cdf da gamafrom scipy.stats import gammaimport scipy.stats as spsdef pgama(x, lamb =1.0):if lamb <=0:print('lambda deve ser maior que 0')returnif (x >=0): a = x +1.0 cdf =1- gamma.cdf(lamb, a)else: cdf =0return cdf# Exemplolamb =0.85x =3.0pgama(x, lamb)sps.poisson.cdf(x, lamb)
np.float64(0.9888689674521238)
np.float64(0.9888689674521238)
6.3 Modelos Probabilísticos Contínuos
Para obtermos a função de distribuição ou a inversa da função de distribuição de modelos probabilísticos contínuos via de regra devemos utilizar métodos numéricos. Existem exceções como, por exemplo, o modelo exponencial descrito no início deste capítulo. A grande maioria dos modelos probabilísticos utilizados atualmente faz uso de algoritmos especialmente desenvolvidos para realizar quadraturas em cada caso particular. Estes algoritmos são, em geral, mais precisos do que os métodos de quadraturas, como são chamados os processos de integração numérica. Existem vários métodos de quadraturas numéricas como o método de Simpson, as quadraturas gaussianas e os métodos de Monte Carlo. Vamos apresentar incialmente os métodos de Simpson e de Monte Carlo, que são mais simples e são menos precisos.
Vamos utilizar o modelo normal para exemplificar o uso desses métodos gerais de integração nas funções contínuas de probabilidades. Uma variável aleatória \(X\) com distribuição normal com média \(\mu\) e variância \(\sigma^2\) possui função densidade dada por:
Em geral utilizamos a normal padrão para aplicarmos as quadraturas. Neste caso a média é \(\mu=0\) e a variância é \(\sigma^2=1\). Assim, representamos frequentemente a densidade por \(\phi(z)\), a função de distribuição por \(\Phi(z)\) e a sua inversa por \(\Phi^{-1}(p)\), em que \(0<p<1\). A variável \(Z\) é obtida de uma transformação linear de uma variável \(X\) normal por \(Z=(X-\mu)/\sigma\).
Vamos apresentar de forma bastante resumida a regra trapezoidal estendida para realizarmos quadraturas de funções. Seja \(f_i\) o valor da função alvo no ponto \(x_i\), ou seja, \(f_i=f(x_i)\), então a regra trapezoidal é dada por:
\[
\int_{x_1}^{x_n} f(x)dx = \dfrac{h}{2}(f_1+f_n) + O(h^3f''),
\tag{6.11}\] em que \(h=x_n-x_1\) e o termo de erro \(O(h^3f'')\) significa que a verdadeira resposta difere da estimada por uma quantidade que é o produto de \(h^3\) pelo valor da segunda derivada da função avaliada em algum ponto do intervalo de integração determinado por \(x_1\) e \(x_n\), sendo \(x_1<x_n\).
Esta equação retorna valores muito imprecisos para as quadraturas da maioria das funções de interesse na estatística. Mas se utilizarmos esta função \(n-1\) vezes para fazer a integração nos intervalos \((x_1, x_2)\), \((x_2, x_3)\), \(\cdots\), \((x_{n-1}, x_n)\) e somarmos os resultados, obteremos a fórmula composta ou a regra trapezoidal estendida por:
\[
\int_{x_1}^{x_n} f(x)dx = h\left(\dfrac{f_1}{2}+f_2+f_3+\cdots+f_{n-1}+\dfrac{f_n}{2}\right)
+ O\left(\dfrac{(x_n-x_1)^3f''}{n^2}\right).
\tag{6.12}\] em que \(h=(x_n-x_1)/(n-1)\).
Uma das melhores forma de implementar a função trapezoidal é discutida e apresentada por Press et al. (1992). Nesta implementação inicialmente é tomada a média da função nos seus pontos finais de integração \(x_1\) e \(x_n\). São realizados refinamentos sucessivos. No primeiro estágio devemos acrescentar o valor da função avaliada no ponto médio dos limites de integração e no segundo estágio, os pontos intermediários \(1/4\) e \(3/4\) são inseridos e assim sucessivamente.
Podemos implementar esta rotina de forma iterativa, dinâmica e recursiva:
Calculamos o valor inicial da integral \(S\) considerando os pontos de extremo, da seguinte forma: \[\begin{align*}
S =& \dfrac{(b-a)}{2}\left(f(a)+f(b)\right).
\end{align*}\]
No passo \(n=2\), atualizamos \(S\), inserindo um valor \(x=a+(b-a)/2\) no ponto médio entre \(a\) e \(b\). Calculamos \(f(x)\) e armazenamos em \(sum\). Definimos \(it\) como sendo o número de pontos a ser inserido entre \(a\) e \(b\) por \(it=2^{n-2}\), em que \(n=2\), indica que estamos no segundo passo. Atualizamos \(S\), por \[ S = \dfrac{1}{2}\left(S + (b-a) \times sum / it \right). \tag{6.13}\]
Fazemos \(n=3\), \(4\), \(5\), \(\cdots\) e repetimos o passo \(2\), atualizando \(S\) a partir de seu antigo valor computado no passo anterior usando (Equation 6.13). Para cada valor de \(n\) devemos comparar os valores do passo anterior e atual até que uma dada precisão seja alcançada.
Veja que \(sum\) do passo \(2\) depende de \(it\). Assim, por exemplo, se \(n=3\), \(it=2^1=2\). Devemos computar \(\Delta=(b-a)/it\) e os dois pontos a serem inseridos são \(x_1=a+\Delta/2\) e \(x_2=x_1+\Delta\). Assim, \(sum=f(x_1)+f(x_2)\).
Em um passo geral, \(n\), temos \(it=2^{n-2}\) pontos, \(\Delta=(b-a)/it\), \(x_1=a+\Delta/2\) e \(x_k=x_{k-1}+\Delta\), \(k=2\), \(3\), \(\cdots\), \(it\). Assim, \(sum=\sum_{k=1}^{it} f(x_k)\).
Sejam func() a função de interesse, \(a\) e \(b\) os limites de integração e \(n\) o número de intervalos de integração previamente definido, então podemos obter a função trapzd() adaptando a mesma função implementada em Fortran por Press et al. (1992) da seguinte forma:
# Esta rotina calcula o n-ésimo estágio de refinamento da # integração trapezoidal estendida, em que, func é uma # função externa de interesse que deve ser chamada para # n=1, 2, etc. e o valor de s deve ser retornado a função# em cada nova chamada.import mathdef trapzd(func, a, b, s, n):if n ==1: s =0.5* (b - a) * (func(a) + func(b))else: it =2**(n -2) dl = (b - a) / it # espaço entre pontos x = a +0.5* dl soma =0.0for j inrange(it): soma += func(x) x += dl# refina o valor de s s =0.5* (s + (b - a) * soma / it)return s# função para executar quadraturas de # funções definidas em func()# até que uma determinada # precisão tenha sido alcançadadef qtrap(func, a, b): eps =1.0e-11 nmax =30 olds =-1.e30# impossível valor para quadratura inicial n =1 fim =0 s =-1.0e15# valor arbitrário para iniciar o loopwhileabs(s-olds) >= eps *abs(olds) and fim ==0: olds = s s = trapzd(func, a, b, s, n) n = n +1if n > nmax: fim =1if n > nmax:print('Limite de passos ultrapassado!')returnreturn s
Devemos chamar a função qtrap() especificando a função de interesse func() e os limites de integração. Assim, para a normal padrão devemos utilizar as seguintes funções:
# fdp da normal padrãodef dnorm(x): fx = (1.0/ (2.0* math.pi)**0.5) * math.exp(-x**2/2)return fxdef pnorm(x): p = qtrap(dnorm, 0.0, abs(x))if x >0: p +=0.5else: p =0.5- preturn p# exemploz =1.96print(pnorm(z))print(sps.norm.cdf(z))
0.9750021048512256
0.9750021048517795
É evidente que temos métodos numéricos gerais mais eficientes do que o apresentado. As quadraturas gaussianas representam uma classe de métodos que normalmente são mais eficientes que este apresentado. Eventualmente, existem métodos específicos para obtermos as integrais dos principais modelos probabilísticos que são mais eficientes. A maior eficiência destes métodos específicos se dá por dois aspectos: velocidade de processamento e precisão. Se exisitirem, no Python estas rotinas específicas já estão implementadas. Como ilustração, podemos substituir a função que implementamos pnorm() pela pré-existente no Python normal.cdf() do scipy.stats. Vamos ilustrar um destes algoritmos especializados para obtermos a função de distribuição da normal padrão. O algoritmo de Hasting possui erro máximo de \(1\times10^{-6}\) e é dado por:
\[
\Phi(x) = \left\{\begin{array}{ll}
G & \textrm{ se } x \le 0 \\
1-G & \textrm{ se } x > 0
\end{array}
\right.
\tag{6.14}\] sendo \(G\) dado por
\[\begin{align*}
G = (a_1\eta+a_2\eta^2+a_3\eta^3+a_4\eta^4+a_5\eta^5)\phi(x)
\end{align*}\] em que \[\begin{align*}
\eta = \dfrac{1}{1+0,2316418|x|}
\end{align*}\] e \(a_1 = 0,319381530\), \(a_2 = -0,356563782\), \(a_3 = 1,781477937\), \(a_4 = -1,821255978\) e \(a_5 = 1,330274429\).
O resultado da implementação deste procedimento é:
# CDF da normal padrão: # aproximação de Hastingdef phnorm(x): eta =1/ (1+abs(x) *0.2316418) a1 =0.319381530; a2 =-0.356563782 a3 =1.781477937; a4 =-1.821255978 a5 =1.330274429 phi =1/ (2* math.pi)**0.5* math.exp(-x * x /2) g = (a1*eta+a2*eta**2+a3*eta**3+a4*eta**4+a5*eta**5)*phiif (x <=0): cdf = g else: cdf =1- greturn cdf# exemploz =1.96p = phnorm(z)p
0.9750021668514388
Com o uso desta função ganhamos em precisão, principalmente para grandes valores em módulo do limite de integração superior e principalmente ganhamos em tempo de processamento. Podemos ainda abordar os métodos de Monte Carlo, que são especialmente úteis para integrarmos funções complexas e multidimensionais. Vamos apresentar apenas uma versão bastante rudimentar deste método. A ideia é determinar um retângulo que engloba a função que desejamos integrar e bombardearmos a região com pontos aleatórios \((u_1,\, u_2)\) provenientes da distribuição uniforme.
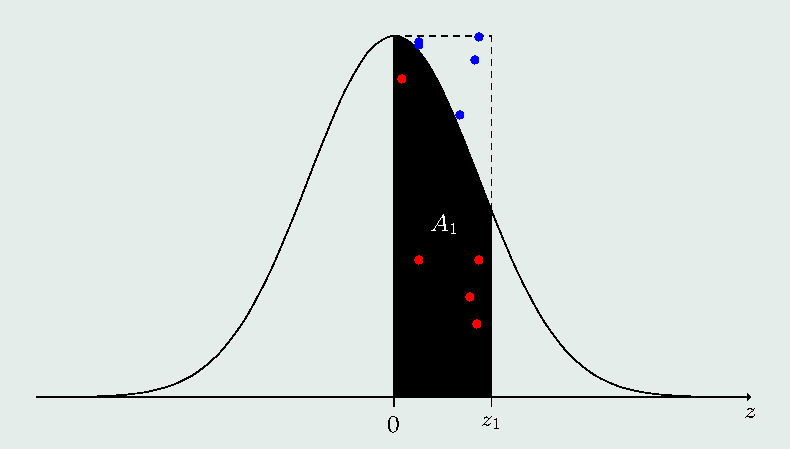
Contamos o número de pontos sob a função e determinamos a área correspondente, a partir da proporcionalidade entre este número de pontos e o total de pontos simulados em relação a área sob a função na região de interesse em relação à área total do retângulo. Se conhecemos o máximo da função \(f_{max}\), podemos determinar este retângulo completamente. Assim, o retângulo de interesse fica definido pela base (valor entre \(0\) e \(z_1\) em módulo, sendo \(z_1\) fornecido pelo usuário) e pela altura (valor da densidade no ponto de máximo). Assim, a área deste retângulo é \(A = |z_1|f_{max}\). No caso da normal padrão, o máximo obtido para \(z=0\) é \(f_{max} = 1/\sqrt{2\pi}\) e a área do retângulo \(A=|z_1|/\sqrt{2\pi}\). Se a área sob a curva, que desejamos estimar, for definida por \(A_1\), podemos gerar números uniformes \(u_1\) entre \(0\) e \(|z_1|\) e números uniformes \(u_2\) entre \(0\) e \(f_{max}\). Para cada valor \(u_1\) gerado calculamos a densidade \(f_1=f(u_1)\). Assim, a razão entre as áreas \(A_1/A\) é proporcional a razão \(n/N\), em que \(n\) representa o número de pontos \((u_1, u_2)\) para os quais \(u_2\le f_1\) e \(N\) o número total de pontos gerados. Logo, a integral é obtida por \(A_1 = |z_1|\times f_{max}\times n/N\), em que \(z_1\) é o valor da normal padrão para o qual desejamos calcular a área que está compreendida entre \(0\) e \(|z_1|\), para assim obtermos a função de distribuição no ponto \(z_1\), ou seja, para obtermos \(\Phi(z_1)\). Assim, se \(z_1\le 0\), então \(\Phi(z_1)=0,5-A_1\) e se \(z_1>0\), então \(\Phi(z_1)= 0,5+ A_1\). Veja a seguinte figura ilustrativa:
Para o caso particular da normal padrão, implementamos a seguinte função:
# Quadratura da normal padrão # via simulação Monte Carloimport numpy as npdef mcpnorm(x, N =2000):max=1/ (2* math.pi)**0.5 z =abs(x) u1 = np.random.uniform(0, z, N) # 0 < u1 < z u2 = np.random.uniform(0, max, N) # 0 < u2 < max f1 = (1/(2*math.pi)**0.5)*np.exp(-u1**2/2) # f1(u1): N(0,1) n =len(f1[u2 <= f1]) g = n / N *max* zif (x <0): cdf =0.5- gelse: cdf =0.5+ greturn(cdf)# exemplo z =1.96N =1500000mcpnorm(z, N)print('Erro de MC: ',1/ N**0.5)
0.9747985060430233
Erro de MC: 0.0008164965809277261
Outra forma de obtermos uma aproximação da integral
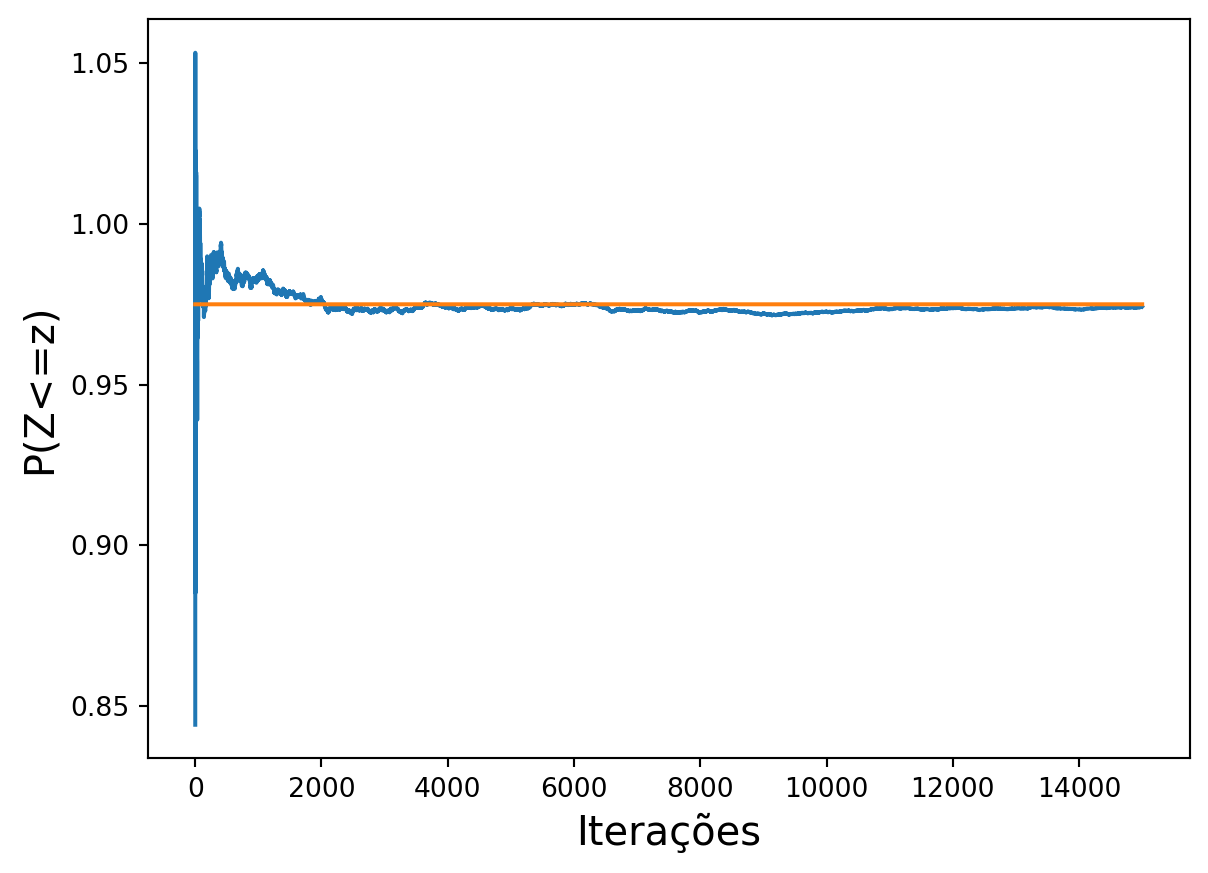
em que \(\phi(t)=1/\sqrt{2\pi}\times\exp\{-t^2/2\}\) é a função densidade normal padrão avaliada no ponto \(t\) e \(\Delta z = abs(z) - 0\). A ordem de erro desse processo é dada por \(O(m^{-1/2})\). O programa Python para obter o valor da função de distribuição normal padrão \(\Phi(z)\) utilizando essas ideias é apresentado a seguir. Por meio de uma comparação dessa alternativa Monte Carlo com a primeira podemos verificar que houve uma grande diminuição do erro de Monte Carlo no cálculo dessa integral, nessa nova abordagem. Muitas variantes e melhorias nesse processo podem ser implementadas, mas nós não iremos discuti-las aqui.
# Quadratura da normal padrão via simulação # Monte Carlo. Segunda forma de obter a # integral: forma clássicaimport numpy as npimport mathimport scipy.stats as spsimport matplotlibimport matplotlib.pyplot as pltdef pmcnorm(z, m =2000): x = np.random.uniform(0, abs(z), m) p = (1/(2* math.pi)**0.5)*np.exp(-(x**2)/2) p =abs(z) * np.mean(p)if z <0: p =0.5- pelse: p +=0.5return p# Exemplom =15000# número de pontos muito inferior ao caso anteriorz =1.96pmcnorm(z, m) # Estimativa de Monte Carlop = sps.norm.cdf(z) # valor real p# Ordem de erro: O(m^(-1/2))1/m**0.5# verificação da convergêncianp.random.seed(1000)x = np.random.uniform(0, abs(z), m)pdf = (1/(2*math.pi)**0.5) * np.exp(-(x**2)/2)if (z <0): cdf =0.5-abs(z) * np.cumsum(pdf) / np.arange(1,m+1) else: cdf =0.5+abs(z) * np.cumsum(pdf) / np.arange(1,m+1)plt.plot(np.arange(1,m+1), cdf)plt.plot(np.arange(1,m+1), [p]*m)plt.xlabel('Iterações', fontsize=15)plt.ylabel('P(Z<=z)', fontsize=15)
np.float64(0.971940047445516)
np.float64(0.9750021048517795)
0.00816496580927726
Text(0.5, 0, 'Iterações')
Text(0, 0.5, 'P(Z<=z)')
6.4 Quadraturas Gaussianas
As quadraturas gaussianas desempenham um papel preponderante na estatística, pois os principais algoritmos de obtenção de probabilidades e quantis utilizam tais métodos implicitamente. Nesta seção, apresentaremos, de forma bastante simplificada e sem aprofundar nos aspectos matemáticos mais técnicos, o principal método de quadratura gaussiana. Os interessados em uma maior pormenorização desses aspectos podem consultar inúmeros livros específicos. Recomendamos por exemplo a leitura de Quarteroni, Sacco, and Saleri (2000).
A base dessas quadraturas são as interpolações baseadas em polinômios ortogonais. Seu uso extrapola o tema das quadraturas numéricas, podendo ser usados para aproximar soluções de quadrados mínimos e diferenciação numérica. Uma quadratura gaussiana de \(n\) pontos é aquela que fornece resultados exatos para a integração de um polinômio de grau igual ou inferior a \(2n-1\). O domínio das quadraturas é, sem perda de generalidade e por convenção, assumido como sendo \([-1, 1]\). A regra geral para a quadratura gaussiana de \(n\) pontos para uma função \(f(x)\), no domínio \([-1, 1]\), é dada por \[
\int_{-1}^1 f(x) dx \approx \sum_{i=1}^n w_i f(x_i),
\tag{6.15}\] em que \(x_i\) e \(w_i\) são denominados de nós e pesos, respectivamente, da quadratura.
Os nós são valores do intervalo \([-1, 1]\) e os pesos são positivos. Devemos escolhê-los de forma apropriada para que o resultado da integral seja aproximado de forma acurada pela soma da direita. Muitas vezes, usamos uma função peso \(w(x_i)\), tal que a integral (Equation 6.15) possa ser representada por \[
\int_{-1}^1 f(x) dx = \int_{-1}^1 w(x)g(x) dx \approx \sum_{i=1}^n w_i g(x_i),
\tag{6.16}\] em que \(g(x)\) é tal que \(f(x)\)\(=\)\(w(x)g(x)\) e \(w_i\) nesse caso são pesos alternativos.
Por exemplo, para o caso específico da função \(f(x)\)\(=\)\(e^{2x}\), usando pesos \(w_1\)\(=\)\(w_2\)\(=\)\(1\) e nós \(x_1\)\(=\)\(\sqrt{3}/3\) e \(x_2\)\(=\)\(-\sqrt{3}/3\), no domínio de \(-1\) a \(1\) resulta em \[\begin{align*}
\int_{-1}^1 e^{2x}dx \approx f(\sqrt{3}/3) + f(-\sqrt{3}/3)=3,4882.
\end{align*}\]
O valor exato da integral é \[\begin{align*}
\int_{-1}^1 e^{2x}dx =& \left[\dfrac{e^{2x}}{2}\right]_{-1}^{1}=3,6269.
\end{align*}\]
É surpreendente que a soma de \(f(x_1)\)\(+\)\(f(x_2)\) resulte em valores exatos para polinômios de grau até \(3\), \(2n-1\), pois \(n\)\(=\)\(2\). O que temos que fazer é encontrar mecanismos para obter os pesos e os nós de integração. Para um intervalo de integração diferente de \([-1, 1]\), ou seja, \([a, b]\), \(b>a\), temos que a seguinte transformação não altera a precisão da integração \[
\begin{array}{rl}
\int_{a}^b f(x) dx =& \dfrac{b-a}{2} \int_{-1}^1 f\left(\dfrac{b-a}{2}x + \dfrac{a+b}{2}\right)dx\nonumber\\
\approx & \dfrac{b-a}{2} \sum_{i=1}^n w_i f\left(\dfrac{b-a}{2}x_i + \dfrac{a+b}{2}\right).
\end{array}
\tag{6.17}\]
Vale a pena ressaltar que os nós utilizados nas quadraturas são as raízes dos polinômios ortogonais de alguma das famílias gaussianas, normalmente empregadas. Entre elas, podemos citar os polinômios de Legendre, Laguerre, Hermite, Chebyshev e Jacobi. Descreveremos apenas a quadratura Gauss-Legendre na sequência.
A quadratura denominada Gauss-Legendre é utilizada para intervalos de integração definidos por \([-1, 1]\), podendo ser extrapolado para intervalos mais gerais, se utilizarmos a expressão (Equation 6.17). Assim, para o domínio \([-1, 1]\), a quadratura Gauss-Legendre pode ser aplicada por \[
\int_{a}^b f(x) dx \approx \left\{ \begin{array}{ll}
\displaystyle \sum_{i=1}^n w_i f(x_i) & \textrm{para } a=-1\textrm{ e } b=1 \\
\displaystyle \sum_{i=1}^n w_i g(y_i) & \textrm{para } a \textrm{ e } b \textrm{ reais quaisquer,}
\end{array}
\right.
\tag{6.18}\] em que \(g(y)\) é dada por \[
g(y)= \dfrac{b-a}{2} f\left(\dfrac{b-a}{2}x + \dfrac{a+b}{2}\right),
\tag{6.19}\] em que \(y\)\(=\)\((b-a)x/2\)\(+\)\((b+a)/2\).
O próximo passo, na aplicação das quadraturas gaussianas, é calcular os nós e pesos para cada uma delas. Apresentaremos isso, na forma de uma sequência de passos. Utilizaremos as seguintes quantidades para todos os métodos. O escalar \(\mu_0\) que é definido por
e os vetores de coeficientes \(\mathbf{a}\)\((n\)\(\times\)\(1)\) e \(\mathbf{b}\)\((n-1\)\(\times\)\(1)\), sendo \(n\) o número de pontos da quadratura a ser realizada.
Posteriormente, ainda utilizaremos uma matriz denotada por \(\mathbf{J}\), \((n\)\(\times\)\(n)\), para a qual obteremos os autovalores e autovetores. Como utilizaremos um problema de álgebra, solucionado pela obtenção de autovalores e autovetores, esse método é conhecido como algoritmo de Golub–Welsch. Descreveremos, inicialmente, a obtenção dos vetores \(\mathbf{a}\) e \(\mathbf{b}\) e da constante \(\mu_0\) para o método de quadratura Gauss-Legendre. Detalhes técnicos de como isso pode ser realizado e as bases teóricas podem ser encontradas em Quarteroni, Sacco, and Saleri (2000).
Para a quadratura Gauss-Legendre temos:
faça \(\mu_0\)\(=\)\(2\);
\(\mathbf{a}=\mathbf{0}\)\((n\)\(\times\)\(1)\);
\(\mathbf{b}=[b_j]\)\((n-1\)\(\times\)\(1)\), tal que
Definidas as quantidades necessárias \(\mathbf{a}\), \(\mathbf{b}\) e \(\mu_0\), devemos aplicar a segunda parte do algoritmo para obter os nós \(x_i\)’s e os pesos \(w_i\)’s, \(i=1\), \(2\), \(\ldots\), \(n\). Utilizamos, para isso, o algoritmo de Golub–Welsch, pelo qual determinamos a matriz \(\mathbf{J}\) a partir dessas quantidades e determinamos seus autovalores e autovetores. A matriz \(\mathbf{J}\) é tridiagonal simétrica definida por \[\begin{align*}
\mathbf{J} =& \left[\begin{array}{llllll}
a_1 & b_1 & 0 & \ldots & \ldots & \ldots \\
b_1 & a_2 & b_2 & 0 & \ldots & \ldots \\
0 & b_2 & a_3 & b_3 & 0 & \ldots \\
0 & \ldots & \ldots & \ldots & \ldots & 0 \\
\ldots & \ldots & 0 & b_{n-2} & a_{n-1} & b_{n-1} \\
\ldots & \ldots & \ldots & 0 & b_{n-1} & a_{n}
\end{array} \right].
\end{align*}\]
Determinamos os autovalores e autovetores de \(\mathbf{J}\) e os denotamos por \[\begin{align*}
\mathbf{x}^*=& \left[\begin{array}{c}
x_1^* \\
x_2^* \\
\vdots\\
x_n^*
\end{array}
\right] &\textrm{ e }&& \mathbf{P}=& \left[\begin{array}{cccc}
p_{11} & p_{21} & \cdots & p_{n1} \\
p_{12} & p_{22} & \cdots & p_{n2} \\
\vdots & \vdots & \ddots & \vdots \\
p_{1n} & p_{2n} & \cdots & p_{nn}
\end{array}
\right],
\end{align*}\]
respectivamente.
Modificamos a notação usual para representar os elementos de uma matriz. Assim, verificamos que na matriz \(\mathbf{P}\), o primeiro índice do elemento \(p_{ij}\) refere-se ao índice do \(i\)-ésimo autovetor e o segundo índice ao \(j\)-ésimo elemento desse autovetor. Por isso, a notação não usual dos índices nessa matriz. Portanto, cada coluna de \(\mathbf{P}\), corresponde a um dos \(n\) autovetores associados a cada um dos autovalores \(x^*_i\) ordenados em ordem decrescente.
Em seguida, podemos obter os nós (pontos), tomando simplesmente os autovalores em ordem crescente, ou seja, o vetor dos nós \(\mathbf{x}\), com componentes \(x_i\), é definido por
\[
\mathbf{x}= \left[\begin{array}{c}
x_1 \\
x_2 \\
\vdots\\
x_n
\end{array}
\right]=\left[\begin{array}{c}
x_n^* \\
x_{n-1}^* \\
\vdots\\
x_1^*
\end{array}
\right],
\tag{6.20}\] em que \(x_i^*\) é o \(i\)-ésimo autovalor da matriz tridiagonal \(\mathbf{J}\).
Podemos constatar que os nós são os autovalores dessa matriz apresentados em ordem reversa, ou seja, em ordem crescente ao invés da habitual forma de apresentá-los, que é a ordem decrescente. Finalmente, podemos obter os pesos como sendo uma função de \(\mu_0\) e dos primeiros elementos de cada autovetor de \(\mathbf{J}\), também considerado em ordem reversa, considerando as ordenações clássicas do maior para o menor autovalor. Essa função busca realizar uma normalização adequada para garantir a validade da quadratura.
Assim, temos que os pesos das quadraturas são obtidos por \[
\mathbf{w}= \left[\begin{array}{l}
w_1 \\
w_2 \\
w_3 \\
\vdots \\
w_{n-1} \\
w_n
\end{array}
\right]=\mu_0\left[\begin{array}{l}
p_{n,1}^2 \\
p_{n-1,1}^2 \\
p_{n-2,1}^2 \\
\vdots \\
p_{2,1}^2 \\
p_{1,1}^2
\end{array}
\right],
\tag{6.21}\] sendo \(p_{ij}\) o \(j\)-ésimo elemento do \(i\)-autovetor de \(\mathbf{J}\) correspondente ao \(i\)-autovalor \(x_i^*\).
Podemos observar que os valores \(w_i\)’s dependem de \(p_{ij}\) em ordem reversa de importância, sendo essa ordem determinada pelos autovalores de \(\mathbf{J}\).
Com os pesos, nós e funções pesos, quando ela não for a unidade, podemos aplicar os métodos de quadraturas apresentados anteriormente. Nosso próximo passo é implementar funções para obter os pesos e os nós e exemplificarmos.
# Função para obter nós e pesos# da quadratura Gauss-Legendreimport numpy as npimport scipy as spdef gausslegendquad(n): n =int(n)if n <0:print('É necessário um número não negativo de nós!')returnif n ==0:return {'xi':[], 'wi': []} i = np.arange(1, n) mu0 =2 b = i / np.sqrt(4* i**2-1) J = np.zeros((n*n)) J[(n +1) * (i-1) +1] = b J[(n +1) * i -1] = b J = J.reshape(n, n) va, ve = sp.linalg.eigh(J) w = ve[0,:] w = mu0 * w**2return {'xi': va, 'wi': w}# função genérica para obter a # quadratura no [-1,1]def quadgl(func, n =8): gl = gausslegendquad(n) res = np.sum(gl['wi'] * func(gl['xi']))return res# exemplo: f(x) = exp(2x)# int_{-1}^{1} f(x) dx - vetorizadadef e2x(x):return np.exp(2*x)# função polinomialdef p3(x):return x**3-0.4*x**2+2.3*x+5# Exemplosn =4gausslegendquad(n)n =8print('e^(2x): ',quadgl(e2x, n))print('Valor exato: ',(e2x(1)-e2x(-1))/2)print('p3: ',quadgl(p3, 2))print('Valor exato wolfram: ',9.73333)
e^(2x): 3.626860407846865
Valor exato: 3.626860407847019
p3: 9.73333333333333
Valor exato wolfram: 9.73333
No exemplo anterior, usamos a função sp.linalg.eigh() do scipy.linalg, pois a função np.linalg.eig() não retorna os autovalores necessariamente em ordem. A função eigh, por sua vez, retorna os autovalores ordenados, mas em ordem crescente de valores e não na ordem decrescente, como é feito em muitos outros programas. Podemos aplicar na normal as quadraturas, para ilustrarmos os casos em que os limites não são \(-1\) e \(1\), incluindo os exemplos anteriores.
import mathimport scipy as sp# função genérica para trocar os # limites de integração de -1 a 1 # para a e b (finitos)def hx(func, x, a =-1, b =1): aux = (b - a) /2 h = aux * func(aux * x + (a + b) /2)return h# modificação da quadGL para contemplar# outros limites que não sejam o -1 e 1def quadglab(func, n =8, a =-1, b =1): gl = gausslegendquad(n) h = hx(func, gl['xi'], a, b) res = np.sum(gl['wi'] * h)return res# X ~ N(mu, sig)def pnormal(x, mu =0, sigma =1, n =16):if math.isclose(x, mu):return0.5else:if math.isclose(mu, 0) and math.isclose(sigma, 1): z = xelse: z = (x - mu) / sigma res = quadglab(sp.stats.norm.pdf, n, 0, abs(z)) if (x < mu): res =0.5- reselse: res +=0.5return res # integrar e2x de 1 até 3a =1b =3quadglab(e2x, 8, a, b)print('Valor exato: ',(e2x(b)-e2x(a))/2)quadglab(p3, 2, a, b) # valor exato 35,73333x =1.96pnormal(x)print('Valor exato: ',sp.stats.norm.cdf(x))
np.float64(198.01986869689384)
Valor exato: 198.01986869690222
np.float64(35.73333333333333)
np.float64(0.9750021048517794)
Valor exato: 0.9750021048517795
Nas quadraturas anteriores, podemos substituir nossa função que calcula os nós e os pesos, por outra, que utiliza um método de obtenção de autovalores e autovetores mais eficiente. Esse método é aplicável a matrizes simétricas tridiagonais. O script a seguir apresenta essa implementação. Precisamos apenas fornecer um vetor com a diagonal da matriz e outro com os elementos das duas diagonais secundárias, que são idênticos. A função utilizada foi a sp.linalg.eigh_tridiagonal() da biblioteca scipy.
# Função para obter nós e pesos# da quadratura Gauss-Legendre# Essa versão dispensa a criação # da matriz J, por aplicar um# processo de obtenção de # autovalores e autovetores em # matrizes tridiagonais - + rápidoimport numpy as npimport scipy as spdef gausslegendquad2(n): n =int(n)if n <0:print('É necessário um número não negativo de nós!')returnif n ==0:return {'xi':[], 'wi': []} i = np.arange(1, n +1) i1 = np.delete(i,n -1) mu0 =2 b = i1 / np.sqrt(4* i1**2-1) a = np.zeros(n) va, ve = sp.linalg.eigh_tridiagonal(a, b) w = ve[0,:] w = mu0 * w**2return {'xi': va, 'wi': w}n =4gausslegendquad2(n)
Vamos apresentar o método numérico de Newton-Raphson para obtermos a solução da equação
\[\begin{align*}
z =& \Phi^{-1}(p),
\end{align*}\]
em que \(0<p<1\) é o valor da função de distribuição da normal padrão, \(\Phi^{-1}(p)\) é a função inversa da função de distribuição normal padrão no ponto \(p\) e \(z\) o quantil correspondente, que queremos encontrar dado um valor de \(p\). Podemos apresentar esse problema por meio da seguinte equação
\[\begin{align*}
\Phi(z) - p =&0,
\end{align*}\] em que \(\Phi(z)\) é a função de distribuição normal padrão avaliada em \(z\). Assim, nosso objetivo é encontrar os zeros da função \(f(z) = \Phi(z) - p\). Em geral, podemos resolver essa equação numericamente utilizando o método de Newton-Raphson, que é um processo iterativo. Assim, devemos ter um valor inicial para o quantil para iniciarmos o processo e no \((n+1)\)-ésimo passo do processo iterativo podemos atualizar o valor do quantil por
\[
z_{n+1}= z_n - \dfrac{f(z_n)}{f'(z_n)},
\tag{6.22}\] em que \(f'(z_n)\) é derivada de primeira ordem da função para a qual queremos obter as raízes avaliada no ponto \(z_n\). Para esse caso particular temos que
\[
z_{n+1}= z_n - \dfrac{\left[\Phi(z_n) - p\right]}{\phi(z_n)},
\tag{6.23}\] sendo \(\phi(z_n)\) a função densidade normal padrão. Como valores iniciais usaremos uma aproximação grosseira, pois nosso objetivo é somente demonstrar o método. Assim, se \(p\) for inferior a \(0,5\) utilizaremos \(z_0=-0,1\), se \(p>0,5\), utilizaremos \(z_0=0,1\). Obviamente se \(p=0\), a função deve retornar \(z=0\). A função a seguir retorna os quantis da normal, dados os valores de \(p\) entre \(0\) e \(1\), da média real \(\mu\) e da variância real positiva \(\sigma^2\), utilizando para isso o método de Newton-Raphson e a função phnorm de Hasting para obtermos o valor da função de distribuição normal padrão.
# função auxiliar para retornar o valor da# função densidade normal padrãodef phi(z):return (1/ (2* math.pi)**0.5* np.exp(-z * z /2))# Método de Newton-Raphson para obtermos quantis # da distribuição normal com média real mu e desvio # padrão real positivo sig, dado 0 < p < 1# utiliza as funções phi(z) e phnorm(z), # apresentadas anteriormentedef qphi(p, mu =0, sig =1, func = phnorm): eps =1e-11if p <=0or p >=1:print('Valor de p deve estar entre 0 e 1!')returnif sig <=0:print('Desvio padrão deve ser maior que 0!') returnifabs(p -0.5) <= eps: z1 =0else:if p <0.5: z0 =-0.1else: z0 =0.1 it =1 itmax =2000 convergiu =Falsewhile convergiu ==False: z1 = z0 - (func(z0) - p) / phi(z0)ifabs(z0 - z1) <= eps *abs(z0) or it > itmax: convergiu =True it = it +1 z0 = z1return {'x': z1 * sig + mu, 'iter': it -1} # Exemplop =0.975mu =0sig =1print('q normal Hasting: ',qphi(p, mu, sig, phnorm))print('q normal Gauss-Legendre: ',qphi(p, mu, sig, pnormal))print('Valor exato: ',sps.norm.ppf(p, mu, sig)) #para fins de comparação
q normal Hasting: {'x': np.float64(1.9599629237446643), 'iter': 8}
q normal Gauss-Legendre: {'x': np.float64(1.9599639845400563), 'iter': 8}
Valor exato: 1.959963984540054
Poderíamos, ainda, ter utilizado o método da secante, uma vez que ele não necessita da derivada de primeira ordem, mas precisa de dois valores iniciais para iniciar o processo e tem convergência mais lenta. O leitor é incentivado a consultar Press et al. (1992) para obter mais detalhes. Também poderia ter sido usada a função pnorm, que utiliza o método trapezoidal. Nesse caso a precisão seria maior, mas o tempo de processamento também é maior. Para isso bastaria usar na chamada como valor do argumento func a função pnorm. Também seria possível chamar mcpnorm ou pmcnorm ou qualquer outra implementação eficiente que tivermos para a quadratura.
Felizmente o Python também possui rotinas pré-programadas para este e para muitos outros modelos probabilísticos, que nos alivia da necessidade de programar rotinas para obtenção das funções de distribuições e inversas das funções de distribuições dos mais variados modelos probabilísticos existentes.
6.6 Funções Pré-Existentes no Python
Na Tabela Table 3.1 apresentamos uma boa parte das rotinas para gerarmos dados dos mais variados modelos probabilísticos contemplados pelo Python. Logo após a tabela mencionada, apresentamos os procedimentos Python da biblioteca scipy.stats para obtermos a função de probabilidade ou densidade, a função de distribuição e a função quantil. Devemos consultar os recursos desta biblioteca para conhecermos os mais diferentes métodos associados a cada um dos seus objetos.
6.7 Exercícios
Comparar a precisão dos três algoritmos de obtenção da função de distribuição normal apresentados neste capítulo. Utilizar a função normal.cdf() como referência.
Utilizar diferentes números de simulações Monte Carlo para integrar a função de distribuição normal e estimar o erro de Monte Carlo relativo e absoluto máximo cometidos em \(30\) repetições para cada tamanho. Utilize os quantis \(1,00\), \(1,645\) e \(1,96\) e a função normal.cdf() como referência.
A distribuição Cauchy é um caso particular da \(t\) de Student com \(\nu=1\) grau de liberdade. A densidade Cauchy é dada por:
Utilizar o método trapezoidal estendido para implementar a obtenção dos valores da distribuição Cauchy. Podemos obter analiticamente também a função de distribuição e sua inversa. Obter tais funções e implementá-las no Python. Utilize as funções scipy.stats pré-existentes para checar os resultados obtidos.
Utilizar o método Monte Carlo descrito nesse capítulo, para obter valores da função de distribuição Cauchy, apresentada no exercício proposto 3. Utilizar alguns valores numéricos para ilustrar e comparar com funções implementadas em Python para esse caso. Qual deve ser o número mínimo de simulações Monte Carlo requeridas para se ter uma precisão razoável.
Press, W. H., B. P. Flannery, S. A. Teukolsky, and W. T. Vetterling. 1992. Numerical Recipes in Fortran: The Art of Scientific Computing. Cambridge: Cambridge University Press.
Quarteroni, A., R. Sacco, and F. Saleri. 2000. Numerical Mathematics. Berlin: springer.