4Geração de Amostras Aleatórias de Variáveis Multidimensionais
Os modelos multivariados ganharam grande aceitação no meio científico em função das facilidades computacionais e do desenvolvimento de programas especializados nesta área. Os fenômenos naturais são em geral multivariados. Um tratamento aplicado em um ser, a um solo ou a um sistema não afeta isoladamente apenas uma variável, e sim todas as variáveis. Ademais, as variáveis possuem relações entre si e qualquer mudança em uma ou algumas delas, afeta as outras. Assim, a geração de realizações de vetores ou matrizes aleatórias é um assunto que não pode ser ignorado. Vamos neste capítulo disponibilizar ao leitor mecanismos para gerar realizações de variáveis aleatórias multidimensionais.
4.1 Introdução
Os processos para gerarmos variáveis aleatórias multidimensionais são muitas vezes considerados difíceis pela maioria dos pesquisadores. Uma boa parte deles, no entanto, pode ser realizada no Python com apenas uma linha de comando. Embora tenhamos estas facilidades, nestas notas vamos apresentar detalhes de alguns processos para gerarmos dados dos principais modelos probabilísticos multivariados como, por exemplo, a normal multivariada, a Wishart e a Wishart invertida, a \(t\) de Student multivariada e algumas outras distribuições.
Uma das principais características das variáveis multidimensionais é a correlação entre seus componentes. A importância destes modelos é praticamente indescritível, mas podemos destacar a inferência paramétrica, a inferência bayesiana, a estimação de regiões de confiança, entre outras. Vamos abordar nas próximos seções formas de gerarmos realizações de variáveis aleatórias multidimensionais para determinados modelos utilizando o Python para implementarmos as rotinas ou para utilizarmos as rotinas pré-existentes. Nossa aparente perda de tempo, descrevendo funções menos eficientes do que as pré-existentes no Python, tem como razão fundamental permitir ao leitor ir além de simplesmente utilizar rotinas previamente programadas por terceiros. Se o leitor ganhar, ao final da leitura deste material, a capacidade de produzir suas próprias rotinas e entender como as rotinas pré-existentes funcionam, nosso objetivo terá sido alcançado.
4.2 Distribuição Normal Multivariada
A função densidade de probabilidade normal multivariada de um vetor aleatório \(\mathbf{X}\) é dada por:
em que \(\mathbf{\mu}\) e \(\mathbf{\Sigma}\) são, respectivamente, o vetor de média e a matriz de covariâncias, simétrica e positiva definida, e \(p\) é a dimensão do vetor aleatório \(\mathbf{X}\).
Um importante resultado diz respeito a combinações lineares de variáveis normais multivariadas e será apresentado no seguinte teorema.
Theorem 4.1 (Combinações Lineares) Considere o vetor aleatório normal multivariado \(\mathbf{X}=[X_1, X_2,\cdots, X_p]^\top\) com média \(\mathbf{\mu}\) e covariância \(\mathbf{\Sigma}\) e considere \(\mathbf{C}\) uma matriz \((p\times p)\) de posto \(p\), então a combinação linear \(\mathbf{Y}=\mathbf{C}\mathbf{X}\)\((p\times 1)\) tem distribuição normal multivariada com média \(\mathbf{\mu}_{{\mathbf{Y}}}=\mathbf{C}\mathbf{\mu}\) e covariância \(\mathbf{\Sigma}_{{\mathbf{Y}}}=\mathbf{C}\mathbf{\Sigma}\mathbf{C}^\top\).
Proof. Se \(\mathbf{C}\) possui posto \(p\), então existe \(\mathbf{C}^{-1}\) e, portanto, \[\begin{align*}
\mathbf{X}=\mathbf{C}^{-1}\mathbf{Y}.
\end{align*}\]
O Jacobiano da transformação é \(J=|\mathbf{C}|^{-1}\) e a distribuição de \(\mathbf{Y}\) é dada por \(f_{\mathbf{Y}}(\mathbf{y})=\)\(f_{\mathbf{X}}(\mathbf{x})|J|\). Se \(\mathbf{X}\) tem distribuição normal multivariada, então \[\begin{align*}
f_{\mathbf{Y}}(\mathbf{y}) = & (2\pi)^{-p/2} \left|\mathbf{\Sigma}\right|^{-\frac{1}{2}}
\exp\left\{-\dfrac{1}{2}(\mathbf{C}^{-1}\mathbf{y}-\mathbf{\mu})^\top
\mathbf{\Sigma}^{-1}(\mathbf{C}^{-1}\mathbf{y}-\mathbf{\mu})\right\}|\mathbf{C}|^{-1}\\
\\
= & (2\pi)^{-p/2} |\mathbf{C}|^{-1/2}
\left|\mathbf{\Sigma}\right|^{-\frac{1}{2}}|\mathbf{C}|^{-1/2}\\
&\times \exp\left\{-\dfrac{1}{2}(\mathbf{y}-\mathbf{C}\mathbf{\mu})^\top\left(\mathbf{C}^\top\right)^{-1}
\mathbf{\Sigma}^{-1}\mathbf{C}^{-1}(\mathbf{y}-\mathbf{C}\mathbf{\mu})\right\}\\
\\
= & (2\pi)^{-p/2} \left|\mathbf{C}\mathbf{\Sigma}\mathbf{C}^\top\right|^{-\frac{1}{2}}
\exp\left\{-\dfrac{1}{2}(\mathbf{y}-\mathbf{C}\mathbf{\mu})^\top
\left(\mathbf{C}\mathbf{\Sigma}\mathbf{C}^\top\right)^{-1}(\mathbf{y}-\mathbf{C}\mathbf{\mu})\right\}\\
\end{align*}\] que é a densidade normal multivariada do vetor aleatório \(\mathbf{Y}\) com média \(\mathbf{\mu}_{{\mathbf{Y}}}=\mathbf{C}\mathbf{\mu}\) e covariância \(\mathbf{\Sigma}_{{\mathbf{Y}}}=\mathbf{C}\mathbf{\Sigma}\mathbf{C}^\top\). Portanto combinações lineares de variáveis normais multivariadas são normais multivariadas.
O teorema Theorem 4.1 nos fornece o principal resultado para gerarmos dados de uma normal multivariada. Assim, como nosso objetivo é gerar dados de uma amostra normal multivariada com vetor de médias \(\mathbf{\mu}\) e matriz de covariâncias \(\mathbf{\Sigma}\) pré-estabelecidos, devemos seguir os seguintes procedimentos. Inicialmente devemos obter a matriz raiz quadrada de \(\mathbf{\Sigma}\), representada por \(\mathbf{\Sigma}^{1/2}\). Para isso, vamos considerar a decomposição espectral da matriz de covariâncias dada por \(\mathbf{\Sigma}=\mathbf{P}\mathbf{\Lambda}\mathbf{P}^\top\). Logo, podemos definir a matriz raiz quadrada de \(\mathbf{\Sigma}\) por \(\mathbf{\Sigma}^{1/2}=\mathbf{P}\mathbf{\Lambda}^{1/2}\mathbf{P}^\top\), em que \(\mathbf{\Lambda}\) é a matriz diagonal dos autovalores, \(\mathbf{\Lambda}^{1/2}\) é a matriz diagonal contendo a raiz quadrada destes elementos e \(\mathbf{P}\) é a matriz de autovetores, cada um destes vetor disposto em uma de suas colunas. Desta decomposição facilmente podemos observar que \(\mathbf{\Sigma}=\mathbf{\Sigma}^{1/2}\mathbf{\Sigma}^{1/2}\).
Assim, podemos utilizar o seguinte método para gerarmos uma realização p-variada de uma normal multivariada. Inicialmente devemos gerar um vetor aleatório \(\mathbf{Z}=[Z_1\), \(Z_2\), \(\cdots\), \(Z_p]^\top\) de \(p\) variáveis normais padrão independentes utilizando, por exemplo, o algoritmo de Box-Müller. Isto que dizer que \(\mathbf{\mu}_{\mathbf{Z}} = \mathbf{0}\) e que Cov\((\mathbf{Z})=\mathbf{I}\). Este vetor deve sofrer a seguinte transformação linear: \[
\mathbf{Y} = \mathbf{\Sigma}^{1/2}\mathbf{Z}+\mathbf{\mu}.
\tag{4.2}\]
De acordo com o teorema Theorem 4.1, o vetor \(\mathbf{Y}\) possui distribuição normal multivariada com média \(\mathbf{\mu}_{\mathbf{Y}} =\mathbf{\Sigma}^{1/2} \mathbf{\mu}_{\mathbf{Z}}+\mathbf{\mu} = \mathbf{\mu}\) e matriz de covariâncias \(\mathbf{\Sigma}^{1/2}\mathbf{I}\mathbf{\Sigma}^{1/2} = \mathbf{\Sigma}\). Este será o método que usaremos para obter a amostra \(p\)-dimensional de tamanho \(n\) de uma normal multivariada com média \(\mathbf{\mu}\) e covariância \(\mathbf{\Sigma}\). Para obtermos a matriz raiz quadrada no Python, podemos utilizar o comando para a obtenção da decomposição espectral np.linalg.svd() ou alternativamente o comando linalg.cholesky(a,/,*,upper=False), que retorna o fator de Cholesky de uma matriz positiva definida, que na verdade é um tipo de raiz quadrada. A decomposição do valor singular neste caso se especializa na decomposição espectral, pois a matriz \(\mathbf{\Sigma}\) é simétrica. Geraremos um vetor de variáveis aleatórias normal padrão independentes \(\mathbf{Z}\) utilizando o comando np.random.normal(). Em seguida a transformação Equation 4.2 é realizada.
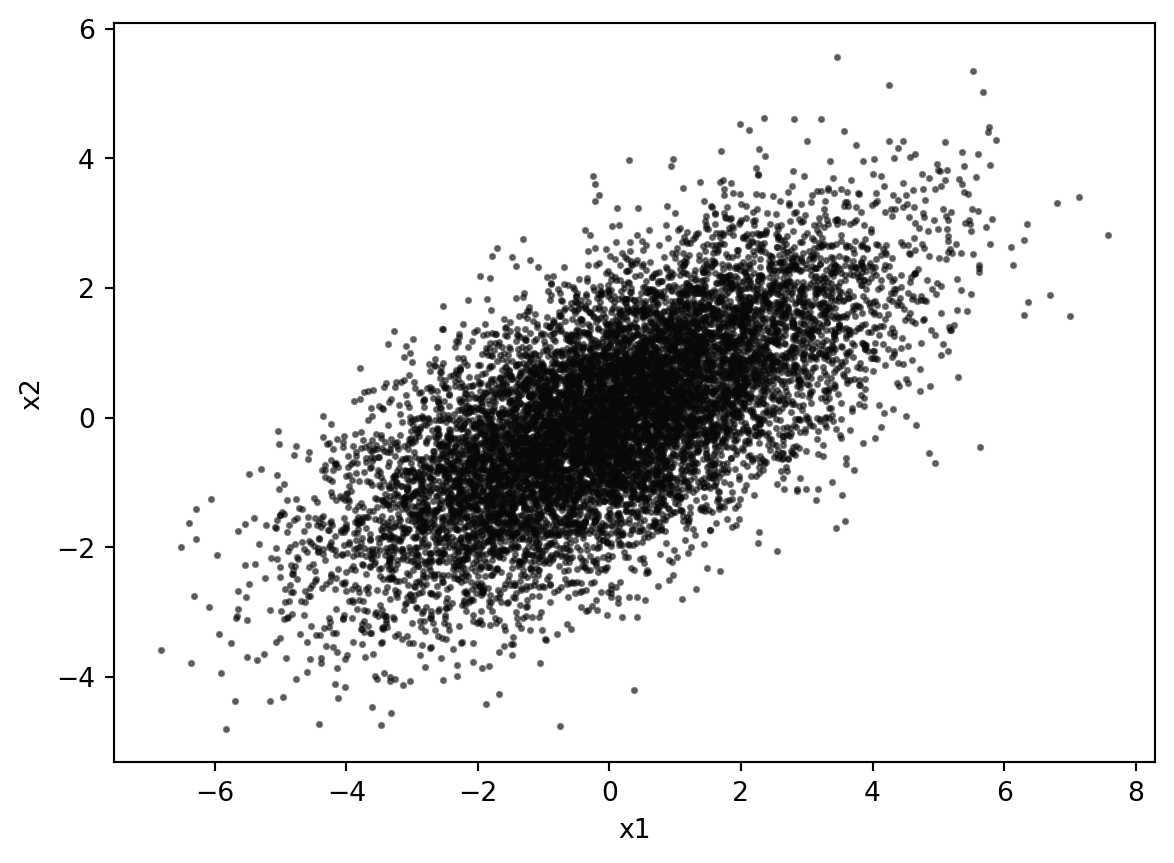
Vamos ilustrar e apresentar o programa de geração de variáveis normais multivariada para um caso particular bivariado \((p=2)\) e com vetor de médias \(\mathbf{\mu}=[10, 50]^\top\) e matriz de covariâncias dada por: \[\begin{align*}
\mathbf{\Sigma} = &
\left[\begin{array}{cc}
4 & 1 \\
1 & 1
\end{array}\right].
\end{align*}\]
O programa resultante é dado por:
# Função Python para gerar n vetores aleatórios normais# multivariados com vetor de médias mu e covariância sigma.# o resultado é uma matriz n x p, sendo p o número de variáveisimport numpy as npimport matplotlib.pyplot as pltdef rnormmv(n, mu, sigma): p = sigma.shape[0] u, d, vt = np.linalg.svd(sigma) sigmaroot = u @ np.diag(d**0.5) @ vtfor i inrange(n): z = np.random.normal(0,1,p)if i ==0: x = sigmaroot @ z + muelse: li = sigmaroot @ z + mu x = np.vstack((x, li))return x# Exemplo de uson =10000sigma = np.array([[4,1],[1,1]]) mu = [10,50]x = rnormmv(n, mu, sigma)np.mean(x, axis =0)np.cov(x,rowvar =False)a = x[:,0]b = x[:,1]plt.scatter(a, b, s =3, c ='#070808', alpha =0.5)plt.xlabel('x1')plt.ylabel('x2')plt.show()
No python temos o gerador do numpy, random.multivariate_normal(mean, cov, size=None, check_valid='warn', tol=1e-8) para gerarmos dados da distribuição normal multivariada. No script a seguir aplicamos a nossa função e a do numpy para gerarmos um número grande de observações e comparamos o desempenho em termos de tempo de processamento. A função do numpy protege o processo, com, por exemplo verificando se a matriz de covariâncias é positiva definida. Em nossa função não utilizamos nenhuma proteção, embora seja possível fazer isso.
# Comparativo de desempenho dos dois geradores de # normais multivariadasfrom datetime import datetimen =60000sigma = np.array([[4,1],[1,1]]) mu = [10, 50]t1 = datetime.now()x = rnormmv(n, mu, sigma)t2 = datetime.now()trnm = t2-t1print('tempo médio da rnormmv: ',trnm.microseconds / n)t1 = datetime.now()x = np.random.multivariate_normal(mu, sigma, size=n)t2 = datetime.now()tnp = t2-t1print('tempo médio da numpy: ',tnp.microseconds / n)# tempo relativoprint('numpy é mais rápido ',trnm.microseconds / tnp.microseconds ,' vezes')
tempo médio da rnormmv: 6.4182
tempo médio da numpy: 0.07496666666666667
numpy é mais rápido 85.6140506891952 vezes
A rotina do numpy foi muitas vezes superior a nossa implementação. Isso em parte é devido ao fato de estar compilada e, talvez, também ao possível método utilizado para obter a matriz raiz quadrada. A troca da matriz raiz quadrada de svd para Cholesky ou pela decomposição espectral, poderia ser feita e o desempenho médio dos procedimentos avaliados, para definirmos a melhor estratégia de implementação. Fizemos uma alteração na nossa implementação. Colocamos um argumento com uma das três opções, para que o usuário escolha qual método utilizar. A obtenção da raiz quadrada foi implementada em uma função separada.
# Função Python para gerar n vetores aleatórios normais# multivariados com vetor de médias mu e covariância sigma.# o resultado é uma matriz n x p, sendo p o número de variáveisdef sigmaroot(sigma, metodo='chol'):if metodo =='svd': u, d, vt = np.linalg.svd(sigma) root = u @ np.diag(d**0.5) @ vtelif metodo =='eig': d, u = np.linalg.eig(sigma) root = u @ np.diag(d**0.5) @ np.transpose(u)else: root = np.linalg.cholesky(sigma) return root# São métodos válidos: 'chol', 'svd' e 'eig'def rnormmv_2(n, mu, sigma, meth ='chol'): p = sigma.shape[0] sigmar = sigmaroot(sigma, meth)for i inrange(n): z = np.random.normal(0,1,p)if i ==0: x = sigmar @ z + muelse: li = sigmar @ z + mu x = np.vstack((x, li))return x
O comparativo entre eles foi apresentado no seguinte script:
# Comparativo de desempenho dos dois geradores de # normais multivariadasn =60000sigma = np.array([[4,1],[1,1]]) mu = [10,50]t1 = datetime.now()x = rnormmv_2(n, mu, sigma,'svd')t2 = datetime.now()tsvd = t2-t1t1 = datetime.now()x = rnormmv_2(n, mu, sigma,'eig')t2 = datetime.now()teig = t2-t1t1 = datetime.now()x = rnormmv_2(n, mu, sigma,'chol')t2 = datetime.now()tchol = t2-t1t1 = datetime.now()x = np.random.multivariate_normal(mu, sigma, size=n)t2 = datetime.now()tnp = t2-t1print('tempo médio da svd: ',tsvd.microseconds / n)print('tempo médio da eig: ',teig.microseconds / n)print('tempo médio da chol: ',tchol.microseconds / n)print('tempo médio da numpy: ',tnp.microseconds / n)# tempo relativoprint('numpy é mais rápido ',tsvd/tnp ,' vezes que svd')print('numpy é mais rápido ',teig/tnp ,' vezes que eig')print('numpy é mais rápido ',tchol/tnp,' vezes que chol')
tempo médio da svd: 8.645183333333334
tempo médio da eig: 5.9836833333333335
tempo médio da chol: 6.105083333333333
tempo médio da numpy: 0.04841666666666666
numpy é mais rápido 522.792082616179 vezes que svd
numpy é mais rápido 467.82134251290876 vezes que eig
numpy é mais rápido 470.328743545611 vezes que chol
Embora nossa função seja relativamente rápida, levando entre 2 e 14 micro segundos para rodar cada observação bivariada neste caso, ela ainda foi bem menos eficiente que rotina numpy. A compilação é fundamental em relação à interpretação. É extremamente simples gerarmos dados de normais multivariadas utilizando a função numpy, o que nos desobriga de programar os nossos próprios geradores aleatórios. Reiteramos que fizemos isso, pois queremos que o nosso leitor e nosso estudante consigam desvendar o que está por trás de cada método deste e também que consiga desenvolver suas habilidades em programação, implementando rotinas sofisticadas como estas.
4.3 Distribuição Wishart e Wishart Invertida
As distribuições Wishart e Wishart invertida são relacionadas às distribuições de matrizes de somas de quadrados e produtos não-corrigidas \(\mathbf{W}\) obtidas de amostras de tamanho \(n-1\) da distribuição normal multivariada com média \(\mathbf{0}\). Considere \(\mathbf{X}_j=[X_1\), \(X_2\), \(\cdots\), \(X_p]^\top\) o \(j\)-ésimo vetor \((j=1\), \(2\), \(\cdots\), \(\nu)\) de uma amostra aleatória de tamanho \(\nu\) de uma normal com média \(\mathbf{0}\) e covariância \(\mathbf{\Sigma}\), então a matriz aleatória \[\begin{align*}
\mathbf{W}=&\sum_{j=1}^{n-1} \mathbf{X}_j\mathbf{X}_j^\top
\end{align*}\] possui distribuição Wishart com \(n-1\) graus de liberdade e parâmetro \(\mathbf{\Sigma}\) (matriz positiva definida).
Da mesma forma, se temos uma amostra aleatória de tamanho \(n\) de uma distribuição normal multivariada com média \(\mathbf{\mu}\) e covariância \(\mathbf{\Sigma}\), a distribuição da matriz aleatória \[\begin{align*}
\mathbf{W}=& \sum_{j=1}^n (\mathbf{X}_j-\mathbf{\bar{X}})(\mathbf{X}_j-\mathbf{\bar{X}})^\top
\end{align*}\] é Wishart com \(\nu = n - 1\) graus de liberdade e parâmetro \(\mathbf{\Sigma}\).
A função densidade Wishart de uma matriz aleatória \(\mathbf{W}\) de somas de quadrados e produtos e representada por \(W_p(\nu,\mathbf{\Sigma})\) é definida por:
\[
f_{\mathbf{W}}(\mathbf{w}|\nu,\mathbf{\Sigma})\! =\! \dfrac{|\mathbf{\Sigma}|^{-\nu/2}|\mathbf{w}|^{(\nu-p-1)/2}}
{2^{\nu p/2}\pi^{p(p-1)/4}
\displaystyle \prod_{i=1}^p
\Gamma\left(\frac{\nu-i+1}{2}\right)}
\exp\left\{-\frac{tr\left(\mathbf{\Sigma}^{-1}\mathbf{w}\right)}{2} \right\}
\tag{4.3}\] em que \(\Gamma(x) = \int_0^\infty t^{x-1}e^{-x}dt\) é função gama.
Assim, para gerarmos variáveis Wishart com parâmetros \(n-1\) graus liberdade inteiro e matriz \(\mathbf{\Sigma}\) positiva definida, podemos utilizar um gerador de amostras aleatórias normais multivariadas e obter a matriz de somas de quadrados e produtos amostrais. Esta matriz será uma realização de uma variável aleatória Wishart, que é uma matriz de dimensão \(p \times p\). A seguinte função pode ser utilizada para obtermos realizações aleatórias de uma Wishart:
# Exemplificação para gerarmos matrizes de somas de quadrados e produtos# aleatórias W com distribuição Wishart(nu, Sigma), nu = n - 1# utiliza o random.multivariate_normal para gerar normais multivariadas.def rwishart(nu, sigma): p = sigma.shape[0] mu = np.full(p, 0) x = np.random.multivariate_normal(mu, sigma, size=nu +1) w = nu * np.cov(x, rowvar=False)return w# Exemplo de usosigma = np.array([[4, 1], [1, 1]])nu =5w = rwishart(nu, sigma)print(w)
Outra distribuição relacionada que aparece frequentemente na inferência multivariada é a Wishart invertida. Considere \(\mathbf{W}\) uma matriz aleatória \(W_p(\nu, \mathbf{\Sigma})\), então a distribuição de \(\mathbf{S} = \mathbf{W}^{-1}\), dada pela função densidade
\[
f_{\mathbf{S}}(\mathbf{s}|\nu,\mathbf{\Sigma})\! =\! \dfrac{|\mathbf{\Sigma}^{-1}|^{\nu/2}|\mathbf{s}|^{-(\nu+p+1)/2}}
{2^{\nu p/2}\pi^{p(p-1)/4}
\displaystyle \prod_{i=1}^p
\Gamma\left(\frac{\nu-i+1}{2}\right)}
\exp\left\{-\frac{tr\left(\mathbf{\Sigma}^{-1}\mathbf{s}^{-1}\right)}{2} \right\}
\tag{4.4}\] é a Wishart invertida que vamos representar por \(W_p^{-1}(\nu, \mathbf{\Sigma})\).
Se quisermos gerar uma matriz aleatória de uma distribuição Wishart invertida em vez de uma Wishart precisamos simplesmente realizar a transformação \(\mathbf{S} = \mathbf{W}^{-1}\). Assim, vamos alterar o programa anterior para gerar simultaneamente realizações aleatórias de distribuição Wishart e Wishart invertida. É importante salientar que em nossa notação os parâmetros da Wishart invertida são aqueles da Wishart. Isto é relevante, pois alguns autores apresentam os parâmetros da Wishart invertida e não da Wishart e devemos estar atentos para este fato, senão geraremos variáveis aleatórias com densidades diferentes.
# Exemplificação para gerarmos matrizes de somas de quadrados e produtos# aleatórias W com distribuição Wishart(nu, Sigma), nu = n - 1# utiliza o pacote mvtnorm para gerar amostras normais.# Exemplificação para gerarmos matrizes de somas de quadrados e produtos# aleatórias W com distribuição Wishart(nu, Sigma), nu = n - 1# e Wishart invertidadef rw_wi(nu, sigma, wi =True): p = sigma.shape[0] mu = np.full(p, 0) x = np.random.multivariate_normal(mu, sigma, size=nu+1) w = nu * np.cov(x, rowvar=False)if wi: iw = np.linalg.pinv(w) res = {'W': w, 'WI': iw}return reselse:return w# Exemplo de usosigma = np.array([[4, 1], [1, 1]])nu =5wi =Trueres = rw_wi(nu, sigma, wi)print('Ambas, W e WI', res)wi =Falseres = rw_wi(nu, sigma, wi)print('Só a Wishart: ', res)
Ambas, W e WI {'W': array([[22.05942053, 6.37066289],
[ 6.37066289, 4.83685105]]), 'WI': array([[ 0.0731606 , -0.09636053],
[-0.09636053, 0.33366346]])}
Só a Wishart: [[13.03938375 5.20022377]
[ 5.20022377 6.76887367]]
Um aspecto importante que precisamos mencionar é sobre a necessidade de gerarmos variáveis Wishart ou Wishart invertida com graus de liberdade reais. Para isso podemos utilizar o algoritmo descrito por Smith and Hocking (1972). Considere a decomposição da matriz \(\mathbf{\Sigma}\) dada por \(\mathbf{\Sigma}=\mathbf{\Sigma}^{1/2}\mathbf{\Sigma}^{1/2}\), que utilizaremos para realizarmos uma transformação na matriz aleatória gerada, que de acordo com propriedades de matrizes Wishart, será Wishart.
Devemos inicialmente construir uma matriz triangular inferior \(\mathbf{T}=[t_{ij}]\)\((i,j=1\), \(2\), \(\cdots\), \(p)\), com \(t_{ii}\sim\sqrt{\chi^2_{\nu+1-i}}\) e \(t_{ij}\sim N(0,1)\) se \(i>j\) e \(t_{ij}=0\) se \(i<j\). Na sequência devemos obter a matriz \(\mathbf{\Gamma}=\mathbf{T}\mathbf{T}^\top\), que possui distribuição \(W_p(\nu, \mathbf{I})\). Desta forma obteremos \(\mathbf{W}=\mathbf{\Sigma}^{1/2}\mathbf{\Gamma}\mathbf{\Sigma}^{1/2}\) com a distribuição desejada, ou seja, com distribuição \(W_p(\nu,\mathbf{\Sigma})\). Fica claro que com esse algoritmo podemos gerar variáveis Wishart com graus de liberdade reais ou inteiros.
# Função mais eficiente para gerarmos matrizes de somas de quadrados# e produtos aleatórias W com distribuição Wishart(nu, Sigma) e# Wishart invertida WI(nu, Sigma)def rwwi_sh(nu, sigma, wi =True): tip =type(sigma)if tip isintor tip isfloat: p =1else: p = sigma.shape[0] df = np.flip(np.arange(nu - p +1, nu +1, 1))if p >1: t = np.diag(np.random.chisquare(df, p)**0.5) t[np.tril_indices(t.shape[0], -1)]=np.random.normal(0,1,int(p*(p-1)/2)) s = np.linalg.cholesky(sigma) else: t = np.random.chisquare(df)**0.5 s = sigma**0.5if tip isintor tip isfloat: w = s**2* t**2else: w = s @ t @ np.transpose(t) @ np.transpose(s) if wi:if tip isintor tip isfloat: iw =1/ welse: iw = np.linalg.pinv(w) res = {'W': w, 'WI': iw}return reselse:return w# Exemplo de usosigma = np.array([[4, 1], [1, 1]])nu =5wi =Trueres = rwwi_sh(nu, sigma, wi)print('Ambas, W e WI', res)wi =Falseres = rwwi_sh(nu, sigma, wi)print('Só a Wishart: ', res)
Ambas, W e WI {'W': array([[8.59639969, 6.3359314 ],
[6.3359314 , 6.87260281]]), 'WI': array([[ 0.36294587, -0.33460396],
[-0.33460396, 0.45398051]])}
Só a Wishart: [[20.39150827 -1.0267872 ]
[-1.0267872 7.13090254]]
Vamos chamar a atenção para alguns fatos sobre esta função, pois utilizamos alguns comandos e recursos não mencionados até o presente momento. Inicialmente utilizamos o comando np.diag(np.random.chisquare(df, p)**0.5) para preencher a diagonal da matriz \(\mathbf{T}\) com realizações de variáveis aleatórias qui-quadrado e em seguida do método diag para transformar o vetor em uma matriz diagonal.
Outro aspecto interessante que merece ser mencionado é o uso do fator de Cholesky no lugar de obter a matriz raiz quadrada de \(\mathbf{\Sigma}\). O fator de Cholesky utiliza a decomposição \(\mathbf{\Sigma} = \mathbf{S}\mathbf{S}^\top\), em que \(\mathbf{S}\) é uma matriz triangular inferior. O Python, por meio da função np.linalg.cholesky(sigma), retorna a matriz \(\mathbf{S}\). Finalmente, se o número de variáveis é igual a \(1\), a distribuição Wishart se especializa na qui-quadrado e a Wishart invertida na qui-quadrado invertida. Assim, quando \(p=1\) o algoritmo retornará variáveis \(\sigma^2 X\) e \(1/(\sigma^2 X)\) com distribuições proporcionais a distribuição qui-quadrado e qui-quadrado invertida, respectivamente, sendo \(X\) uma variável qui-quadrado com \(\nu\) graus de liberdade.
O processamento para o caso escalar foi controlado com o uso do if, pois operações matriciais não são aplicáveis se os argumentos forem escalares inteiros ou float (reais).
4.4 Distribuição t de Student Multivariada
A família de distribuições elípticas é muito importante na multivariada e nas aplicações Bayesianas. A distribuição \(t\) de Student multivariada é um caso particular desta família. Esta distribuição tem particular interesse nos procedimentos de comparação múltipla dos tratamentos com alguma testemunha avaliada no experimento. A função densidade do vetor aleatório \(\mathbf{X} = [X_1, X_2\), \(\cdots\), \(X_p]^\top\)\(\in \mathbb{R}^p\) com parâmetros dados pelo vetor de médias \(\mathbf{\mu} = [\mu_1, \mu_2, \cdots, \mu_p]^\top\)\(\in \mathbb{R}^p\) e matriz simétrica e positiva definida \(\mathbf{\Sigma}\)\((p\times p)\) é
\[\begin{align*}
f_{\mathbf{X}}(\mathbf{x}) = &
\dfrac{g((\mathbf{x}-\mathbf{\mu})^\top\mathbf{\Sigma}^{-1}(\mathbf{x}-\mathbf{\mu}))}{|\mathbf{\Sigma}|^{1/2}}\nonumber \\
=& \dfrac{\Gamma\left(\frac{\nu+p}{2}\right)}{(\pi\nu)^{p/2}\Gamma(\nu/2)|\mathbf{\Sigma}|^{1/2}}
\left[1+\dfrac{1}{\nu}(\mathbf{x}-\mathbf{\mu})^\top\mathbf{\Sigma}^{-1}(\mathbf{x}-\mathbf{\mu})\right]^{-\frac{\nu+p}{2}}
\end{align*}\] em que a função \(g\) é dada por \[g(z) = \dfrac{\Gamma \left( \frac{\nu+p}{2} \right)}{(\pi\nu)^{p/2} \Gamma(\nu/2)} \left(1 + \dfrac{z}{\nu} \right)^{-(\nu+p)/2}.\] A variável aleatória \(\mathbf{X}\) tem média \(\mathbf{\mu}\) e matriz de covariâncias \(\nu\mathbf{\Sigma}/(\nu-2)\) no caso de \(\nu>2\).
Se efetuarmos a transformação \(\mathbf{Y} = \mathbf{\Sigma}^{-1/2} (\mathbf{X} - \mathbf{\mu})\) obteremos a distribuição \(t\) multivariada esférica simétrica, cuja densidade é dada por:
A variável aleatória \(\mathbf{Y}\) terá vetor de médias nulo e covariâncias \(\nu\mathbf{I}/(\nu-2)\) e a densidade terá contornos esféricos de mesma probabilidade.
Vamos apresentar a forma geral para gerarmos variáveis aleatórias p-dimensionais \(t\) multivariada com \(\nu\) graus de liberdade e parâmetros \(\mathbf{\mu}\) e \(\mathbf{\Sigma}\). Seja um vetor aleatório \(\mathbf{Z}\) com distribuição \(N_p(\mathbf{0}, \mathbf{I})\) e a variável aleatória \(U\) com distribuição qui-quadrado com \(\nu\) graus de liberdade, então o vetor aleatório \(\mathbf{Y}\), dado pela transformação \[
\mathbf{Y} = \sqrt{\nu} \dfrac{\mathbf{Z}}{\sqrt{U}},
\tag{4.6}\] possui distribuição \(t\) multivariada esférica com \(\nu\) graus de liberdade. O vetor \(\mathbf{X}\) obtido pela transformação linear
\[
\mathbf{X} = \mathbf{\Sigma}^{1/2} \mathbf{Y}+\mathbf{\mu},
\tag{4.7}\] possui distribuição \(t\) multivariada elíptica com \(\nu\) graus de liberdade e parâmetros \(\mathbf{\mu}\) e \(\mathbf{\Sigma}\).
Devemos aplicar a transformação (Equation 4.7) \(n\) vezes a \(n\) diferentes vetores aleatórios \(\mathbf{Y}\) e variáveis \(U\). Ao final deste processo teremos uma amostra de tamanho \(n\) da distribuição \(t\) multivariada almejada com \(\nu\) graus de liberdade. Assim, para gerarmos dados de uma \(t\) multivariada com dimensão \(p\), graus de liberdade \(\nu\) (não necessariamente inteiro), vetor de média \(\mathbf{\mu}\) qualquer e matriz positiva definida \(\mathbf{\Sigma}\) podemos utilizar a seguinte função Python, substituindo na expressão (Equation 4.7) a matriz raiz quadrada pelo fator de Cholesky \(\mathbf{F}\) de \(\mathbf{\Sigma}\):
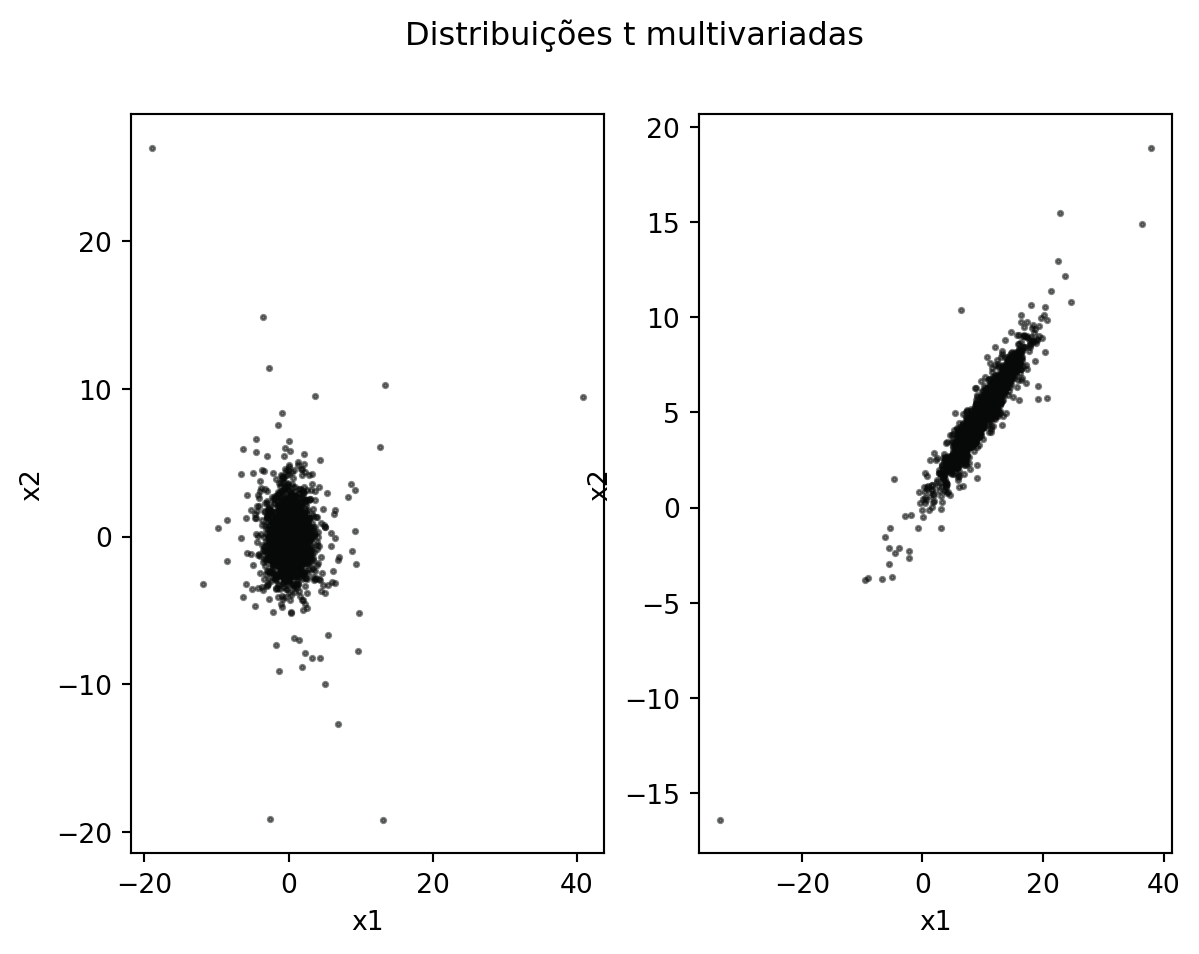
# Função para gerarmos variáveis aleatórias t# multivariadas (n, mu, Sigma, nu). def rtmult(n, mu=[0,0,0], sigma=np.identity(3), df =1): f = np.linalg.cholesky(sigma) p = sigma.shape[0] x = np.random.multivariate_normal(np.zeros(p),np.identity(p),n) q = (np.random.chisquare(df,n) / df)**0.5 x = x / q[:, np.newaxis] @ np.transpose(f) x += np.tile(mu, n).reshape(n,p)return x# Exemplo de uson =3000nu =3mu = [0,0]sigma = np.identity(2)x = rtmult(n, mu, sigma, nu)fig, (ax1, ax2) = plt.subplots(1, 2)fig.suptitle('Distribuições t multivariadas')ax1.scatter(x[:,0], x[:,1], s =3, c ='#070808', alpha =0.5)ax1.set_xlabel('x1')ax1.set_ylabel('x2')mu = [10, 5]sigma = np.array([[4, 1.9], [1.9,1]])x = rtmult(n, mu, sigma, nu)ax2.scatter(x[:,0], x[:,1], s =3, c ='#070808', alpha =0.5)ax2.set_xlabel('x1')ax2.set_ylabel('x2')np.cov(x, rowvar =False)nu * sigma
Graus de liberdade reais positivos podem ser utilizados como argumento da função criada. Foram geradas, no exemplo anterior, duas amostras aleatórias para ilustrar. Foram definidos para os parâmetros \(\mathbf{\mu}\), \(\mathbf{\Sigma}\) e \(\nu\), os valores \([0,\), \(0\), \(0]^\top\), \(\mathbf{I}_3\) e \(3\), respectivamente, como default. Podemos também utilizar a implementação determinada pela função multivariate_t.rvs(mu, sigma, df n), da biblioteca scipy, para gerarmos dados da distribuição \(t\) de Student multivariada.
Existem muitas outras distribuições multivariadas. Vamos mencionar apenas mais duas delas: a log-normal e a normal contaminada multivariadas. A geração de um vetor aleatório de dimensão \(p\) com distribuição log-normal multivariada é feita tomando-se o seguinte vetor \(\mathbf{Y} = [\exp(Z_1)\), \(\exp(Z_2)\), \(\cdots\), \(\exp(Z_p)]^\top\), em que \(\mathbf{Z}\sim N_p(\mathbf{\mu}, \mathbf{\Sigma})\).
# gerador de realizações de variáveis log-normal # multivariada com parâmetros mu e sigmadef rlgnormalmv(n, mu=np.zeros(3), sigma=np.identity(3)): x = np.exp(np.random.multivariate_normal(mu,sigma,n))return x# Exemplo de uso n =7print(rlgnormalmv(n)) # lgnormalmv padrão
Para gerarmos realizações da normal contaminada multivariada consideramos a simulação de um vetor aleatório \(\mathbf{X}\) cuja densidade de probabilidade é dada por:
\[\begin{align*}
f_{\mathbf{X}}(\mathbf{x}) =& \delta (2\pi)^{-p/2}
|\mathbf{\Sigma}_1|^{-1/2}\exp\left\{
-\dfrac{(\mathbf{x}-\mathbf{\mu}_1)^\top\mathbf{\Sigma}_1^{-1}(\mathbf{x}-\mathbf{\mu}_1)}{2}\right\}\nonumber\\
& +(1-\delta)(2\pi)^{-p/2} |\mathbf{\Sigma}_2|^{-1/2}\exp\left\{-\dfrac{(\mathbf{x}
-\mathbf{\mu}_2)^\top\mathbf{\Sigma}_2^{-1}(\mathbf{x}-\mathbf{\mu}_2)}{2}\right\}
\end{align*}\] em que \(\mathbf{\Sigma}_i\) positiva definida, \(i=1, 2\) e \(0\le \delta \le 1\).
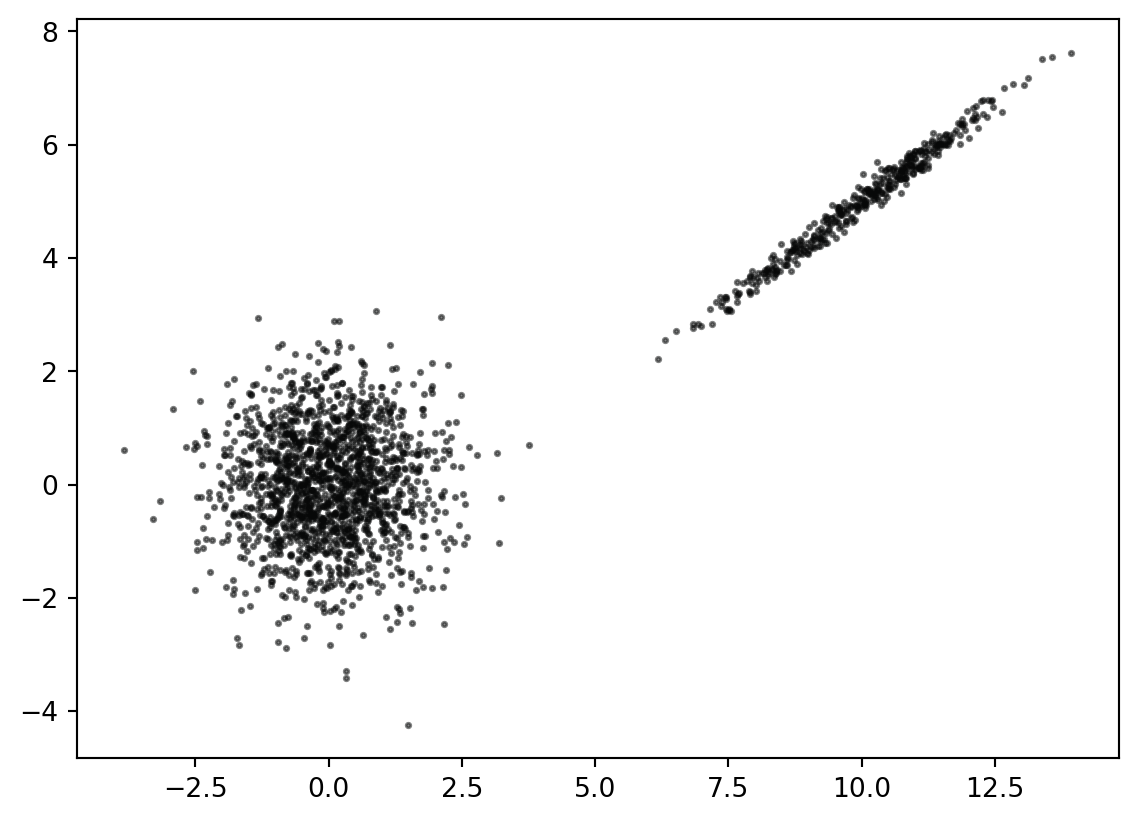
# gerador de variáveis normal contaminada multivariada# com delta sendo a proporção de não-contaminantes: (0, 1)def rncm(n, mu1, mu2, sig1, sig2, delta=0.8): u = np.random.uniform(size=n) p = sig1.shape[0] n1 =len(u[u <= delta]) n2 = n - n1 x = np.zeros(n * p).reshape(n, p)if (n1 >0): li = np.arange(n)[u <= delta] x[li,:] = np.random.multivariate_normal(mu1, sig1, n1)if (n2 >0): li = np.arange(n)[u > delta] x[li,:] = np.random.multivariate_normal(mu2, sig2, n2) return x # Exemplon =20000delta =0.8mu1 = np.zeros(2)sig1 = np.identity(2)mu2 = [-2, -2]sig2 = np.array([[2, 1.4], [1.4, 1]])x = rncm(n, mu1, mu2, sig1, sig2, delta)plt.scatter(x[:,0], x[:,1], s =3, c ='#070808', alpha =0.5)plt.show()
4.6 Exercícios
Gerar uma amostra de tamanho \((n = 10)\) uma distribuição normal trivariada com vetor de médias \(\mathbf{\mu}=[5,10, 15]^\top\) e matriz de covariâncias \[\begin{align*}
\mathbf{\Sigma} = & \left[\begin{array}{ccc}
5 & -1 & 2 \\
-1 & 3 & -2 \\
2 & -2 & 7
\end{array}\right].
\end{align*}\]
Estimar a média e a covariância amostral. Repetir este processo \(1.000\) vezes e estimar a média das médias amostrais e a média das matrizes de covariâncias amostrais. Estes valores correspondem exatamente aos respectivos valores esperados? Se não, apresentar a(s) principal(is) causa(s).
A partir da alteração da função rnormmv que realizamos, comparar o tempo de processamento médio quando for utilizado svd, eig ou cholesky que corresponde a um possível tipo de matriz raiz quadrada de \(\mathbf{\Sigma}\). Verificar se houve melhoria no desempenho em relação ao tempo médio de processamento de cada variável aleatória gerada, vetor \(p\)-dimensional. Testar isso usando modificando \(n\) e \(p\), pois só apresentamos o teste para um único valor de \(p\) e pequeno, \(p=2\).
Sabemos que variáveis Wishart possuem média \(\nu \mathbf{\Sigma}\). Apresentar um programa para verificar se o valor esperado, ignorando o erro de Monte Carlo, é alcançado com o uso das funções apresentadas para gerar variáveis Wishart. Utilizar 10.000 repetições de Monte Carlo. Isso seria uma forma simples, embora não conclusiva, de checar se a função está realizando as simulações corretamente. Serve ao menos para indicar a presença de erro, mas não garante a assertividade.
Implementar funções Python para gerarmos variáveis aleatórias log-normal e normal-contaminada elípticas multivariadas.
Smith, W. B., and R. R. Hocking. 1972. “Algorithm AS 53: Wishart Variate Generator.”Applied Statistics - Journal of the Royal Statistical Society - Series C 21 (3): 341–45.