7Conjuntos e Elementos de Análise Combinatória em Python
Neste capítulo, pretendemos apresentar os conceitos básicos de análise combinatória e de conjuntos, de uma forma bastante simples. Vamos fazer algumas funções simples para cálculo de probabilidades computacionalmente em alguns casos particulares. Vimos no capítulo 1 os objetos conjuntos (set) do Python. O operador set() é usado para criar um conjunto. O argumento da função set() é uma lista ou uma tupla. São imutáveis, não ordenados e não possuem elemento duplicados.
Várias funções podem ser usadas para este tipo de objeto em Python, como pertencimento (in), união (union ou |), interseção (intersection ou &) e diferença simétrica (symmetric_difference ou ^), como foi ilustrado no capítulo 1. Também é possível obter diferenças, tipo A-B entre dois conjuntos A e B.
A análise combinatória nos permite resolver inúmeros problemas de probabilidade. Problemas que ocorrem normalmente são listados a seguir:
selecionar entre \(n\) elementos \(x\) deles, \(0\le x\le n\), sem repetir nenhum elemento (amostragem sem reposição) onde a ordem não importa: combinação;
selecionar entre \(n\) elementos \(x\) deles, \(0\le x\le n\), podendo repetir os elementos selecionados (amostragem sem reposição) onde a ordem importa: arranjos;
distribuir \(n\) elementos em \(x\), \(x= n\), posições de formas diferentes: permutações;
caminhos diferentes possíveis de se percorrer com \(n_1\) possibilidades na primeira etapa, \(n_2\) possibilidades na segunda etapa e assim sucessivamente até \(n_k\) possibilidades na \(k\)-ésima etapa: contagem.
Assim, queremos obter todas as possíveis combinações, permutações, arranjos ou caminhos (contagens) possíveis na resolução de algum problema de probabilidade ou de outra situação em geral.
7.1 Introdução a Análise Combinatória no Python
A análise combinatória e os métodos de contagem são essenciais para se entender probabilidade. No Python podemos computar o número de combinações dado por \[\begin{align*}
\binom{n}{x} =& \dfrac{n!}{x!(n-x)!}, \textrm{ para } 0\le x \le n,
\end{align*}\] por math.comb(n, x). Já á listagem das combinações de \(n\) tomados \(x\) a \(x\) é obtida pelo comando combinations(range(1,n+1), x) do pacote itertools que deve ser importado. O primeiro argumento da função combinations é uma lista, que no caso foi de uma lista indo de \(1\) a \(n\), em que usamos a função range para obter essa lista. Podemos, em vez disso, usar qualquer outra lista. Podemos usar ainda a função comb do scipy.special para obtermos o número de combinações de forma alternativa.
O comando combinations(n, x) do pacote itertools retorna um objeto que deve ser convertido para uma lista com \(\binom{n}{x}\) elementos, em que cada elemento da lista corresponde a uma tupla de \(x\) elementos (a combinação).
O script a seguir ilustra um caso particular destes comandos:
from itertools import combinations from scipy import special as spsimport mathn =4x =2math.comb(n, x)sps.comb(n, x) # resultado é um floatcomb =list(combinations(range(1,n+1), x))print(comb)# listando a combinação 0 da listaprint(comb[0])len(comb) # número de combinações alternativo# retorna uma combinação de letraslist(combinations(['a','b','c'], 2))
O número total de permutações de \(n\) objetos é dado por \(n!\) e com o uso do pacote itertools, podemos listá-las em uma lista de tamanho \(n!\) com cada elemento sendo uma tupla de tamanho \(n\), com a função permutations();
Também podemos tomar os arranjos de \(n\) tomados \(x\) a \(x\), com o mesmo comando, cujo número de arranjos é dado por \[\begin{align*}
A_{n,x}=& \dfrac{n!}{(n-x)!},
\end{align*}\] sendo que no Python esse valor é obtido por meio da função math.perm(n, x).
O script a seguir ilustra estes comandos:
# Obter todas as permutações de n# em n posições - permutação # ou em x posições x<n, arranjo from itertools import permutations import mathn =3# permutaçõesperm =list(permutations(range(1,n+1)))print(perm)# arranjosx =2# x < nmath.perm(n, x)arran =list(permutations(range(1,n+1), x))print(arran) # Imprime as permutaçõesfor i inlist(perm):print(i) type(perm[0])
Para sortearmos permutações ou arranjos de forma aleatória, o comando random.sample(range(1,n+1),n) retorna uma permutação de \(n\) tomados \(n\) a \(n\). Se quisermos um sorteio de \(n\) tomados \(x\) a \(x\)random.sample(range(1,n+1),x), ou seja, um arranjo de um resultado com \(x\) elementos sem repetição (amostra sem reposição). Não é referente ao caso em questão (permutações e arranjos), mas se desejarmos amostragens com reposição, como requerido nos métodos bootstrap, usamos a função random.choices(range(1,n+1),x), em que \(x\) é um valor entre 1 e n. Ambos os comando requerem que importemos a biblioteca random do Python. O script a seguir ilustra estes comandos:
# Obter amostras aleatórias de # permutações ou arranjos # (sem reposição), ou amostras com# reposiçãoimport randomn =5# amostras de permutaçõesamostra = random.sample(range(1,n+1), n)print(amostra)x =3# x < n# amostras de arranjosamostra = random.sample(range(1,n+1), x)print(amostra)# amostras com reposiçãox =3amos = random.choices(range(1,n+1), k=x)print(amos)
[5, 2, 4, 1, 3]
[4, 3, 5]
[4, 3, 1]
7.3 Contagem
O princípio fundamental da contagem, conhecido por princípio multiplicativo, é utilizado para encontrar o número de possibilidades para um evento constituído de \(k\) etapas. As etapas devem ser sucessivas e independentes. Se um evento tem duas \((k=2)\) etapas, sendo que a primeira possui \(n_1\) possibilidades e a segunda, \(n_2\) possibilidades, então existem \(n_1\times n_2\) possibilidades.
Assim, o princípio fundamental da contagem é a multiplicação das opções de cada etapa para determinar o total de possibilidades. Esse conceito é importante para a análise combinatória, área da matemática que reúne os métodos para resolução de problemas incluindo a contagem entre eles e, por isso, é muito útil na investigação para determinar a probabilidade de fenômenos naturais.
Para obtermos todas as possibilidades em \(k\) etapas, cada uma com a mesma quantidade \(n\) de possibilidades criamos uma classe Python com algumas funções. A função contag(n, k) retorna todas as contagens a partir de \(n\) possibilidades em \(k\) etapas, como, por exemplo, com \(n=2\) sexos de animais em \(k=3\) nascimentos, ou \(n=2\) portas de um prédio em \(k=2\) possibilidades, correspondentes às entradas e às saídas do prédio. Também fizemos o mesmo quando temos uma lista (iterador qualquer) de tamanho \(k\) correspondendo às \(k\) etapas em que cada elemento refere-se ao número de possibilidades daquela etapa.
A pergunta, do segundo exemplo, de quais maneiras diferentes uma pessoa pode entrar e sair do edifício com 2 entradas e duas saídas é o que pretendemos listar (enumerar). A função proposta usa um processo recursivo, em que em cada chamada é atualizada a contagem em particular. A recursividade ocorre na função permuta ou permutav, para o caso de uma lista de etapas.
# Classe para obter as contagens de x # possibilidades em cada k etapas: x, k vezes# ou x = [n1,n2,...,nk](lista com k nós).# Usa overload e ilustra a criação # de uma classe Pythonfrom multipledispatch import dispatchimport numpy as npclass Cont:def permuta(self,z, pos, permn, n, k, prim):if prim: z = np.full(k +1, 1) prim =False permun = np.append(permn,[z[1:(k+1)]],axis=0)else: permun = permnif z[pos] < n: z[pos] = z[pos] +1 permun = np.append(permun,[z[1:(k+1)]],axis=0) else: nachei =Trueif pos == k: i = pos -1 paratras =Trueelse: i = pos +1 paratras =Falsewhile nachei and i >=1and i <= k:if z[i] < n: z[i] = z[i] +1if paratras: z[(i+1):(k+1)] =1 permun = np.append(permun,[z[1:(k+1)]],axis=0) pos = k nachei =Falseelse:if (pos == k): i = i -1else: i = i +1if np.sum(z[1:(k+1)]) == n * k:return permunelse:returnself.permuta(z, pos, permun, n, k, prim)def permutav(self,z, pos, permn, x, k, prim):if prim: k =len(x) pos = k z = np.full(k +1, 1) prim =False permun = np.append(permn,[z[1:(k+1)]],axis=0)else: permun = permnif z[pos] < x[pos-1]: z[pos] = z[pos] +1 permun = np.append(permun,[z[1:(k+1)]],axis=0) else: nachei =Trueif pos == k: i = pos -1 paratras =Trueelse: i = pos +1 paratras =Falsewhile nachei and i >=1and i <= k:if z[i] < x[i-1]: z[i] = z[i] +1if paratras: z[(i+1):(k+1)] =1 permun = np.append(permun,[z[1:(k+1)]],axis=0) pos = k nachei =Falseelse:if pos == k: i = i -1else: i = i +1if np.sum(z[1:(k+1)]) ==sum(x):return permunelse:returnself.permutav(z, pos, permun, x, k, prim) @dispatch(int, int) def contag(self, x, k): prim =True permn = np.empty((0, k), int) z = np.array([]) pos = k n = x res =self.permuta(z, pos, permn, n, k, prim)return res@dispatch(list) def contag(self, x): k =len(x) pos = k prim =True permn = np.empty((0, k), int) z = np.array([]) res =self.permutav(z, pos, permn, x, k, prim)return res # Exemplo de usores = Cont()k =3x =3val = res.contag(x, k)print(val) x = [3, 4, 2]res.contag(x)
No exemplo anterior tivemos várias novidades. Criamos uma classe pela primeira vez. Nesta classe implementamos quatro funções. Entre elas, as duas com a função de realizar as listagens de todas as contagens foram implementadas com chamadas recursivas. As outras duas, foram duas versões de uma mesma função com diferentes argumentos, a função contag. Para isso usamos a técnica de overloading. Assim, usamos o pacote multipledispatch de onde importamos from multipledispatch import dispatch. O comando @dispatch(int, int) ou @dispatch(list) antes da definição da função contag indica que ela tem diferentes argumentos. A primeira definição possui dois argumentos inteiros e a segunda, um argumento, correspondente a uma lista. Para exemplificar, criamos um objeto da classe Cont, objeto res, por meio do qual chamamos o método contag duas vezes com argumentos diferentes, o que faz com que ao ser executado, o interpretador escolha a opção apropriada.
Se, por exemplo, quiséssemos obter todas as possibilidades de nascimento quanto ao sexo de famílias de até \(4\) filhos, teríamos o seguinte espaço amostral de nosso experimento com \(2^4\)\(=\)\(16\) elementos:
# Espaço amostral dos filhos # quanto ao sexo# com n = 4 e 0 <= x <= nfilhos = Cont()n =4res = filhos.contag(2, n) -1sexo = ['F','M']type(res[0])print(np.array(sexo)[res])
O Python já tem implementado esses recursos para realizar contagens. A biblioteca itertools possui a função product que faz o mesmo papel de nossas funções implementadas na classe cont.
Vamos relembrar as principais funções dos objetos set, conjuntos em Python, para podermos realizar algumas operações simples. Os conjuntos no Python é uma coletânea de elementos sem a ocorrência de valores com multiplicidades. Os conjuntos são criados pelo método set ou pelo uso de chaves. Portanto, x = set([1,2,3]) ou x={1,2,3} é um conjunto, mas y= [1,2,3,3] não é, por ter elementos repetidos. Se considerassemos o comando y= set([1,2,3,3]), este objeto seria um conjunto, pois o Python elimina automaticamente os elementos repetidos na criação do conjunto.
Os argumentos da função set são as listas ou as tuplas. Podemos de forma eficiente usar os conjuntos para remover elementos duplicados de uma lista ou tupla. Primeiro, aplicamos o operadorset() com o argumento sendo uma lista ou uma tupla e aplicamos o argumento list() ou tupla() no resultado. Outra vantagem dos conjuntos é que eles podem ter elementos de diferentes tipos. Os conjuntos são imutáveis, pois seus elementos não podem ser trocados, mas podemos adicionar e remover elementos de um conjunto em Python. Além do mais, os conjuntos são não ordenados. Vejamos um exemplo de como criar um conjunto.
Podemos adicionar ou remover elementos em um conjunto. Os elementos que são argumentos das funções set.add() ou set.update() devem ser imutáveis como as tuplas ou as strings para o primeiro método e qualquer objeto iterador como as listas, para o segundo. Se o argumento for uma lista, ocorrerá um erro no método add. Para remover um elemento de um conjunto, podemos usar métodos como o set.remove() ou set.discard() ou set.pop(). O primeiro comando remove um elemento específico do conjunto e retorna um erro, se o elemento não existir. O segundo remove o elemento, mas não acusa erro se o elemento não existir, deixando o conjunto como estava anteriormente a sua aplicação. O terceiro remove um elemento de forma aleatória do conjunto e não tem argumento. O método pop retorna o elemento removido e atualiza (modifica) o conjunto no qual foi aplicado. Os métodos add e update diferem no sentido do primeiro não suportar acrescentar uma lista ao conjunto. O método set.clear() remove todos os elementos do conjunto. Veja o script com alguns exemplos:
# adição e remoção de elementos # de um conjuntox = {1,2,3,4}y = [4,5,6,7]x.update(y)xx.add(8)xx.remove(8)xx.discard(9) # não causa erro por não existir em xxx.pop()x
{1, 2, 3, 4, 5, 6, 7}
{1, 2, 3, 4, 5, 6, 7, 8}
{1, 2, 3, 4, 5, 6, 7}
{1, 2, 3, 4, 5, 6, 7}
1
{2, 3, 4, 5, 6, 7}
O Python inclui algumas operações com conjuntos, sendo algumas delas:
set.union(x, y): união dos conjuntos \(x\) e \(y\), que corresponde ao conjunto de todos os elementos presentes em \(x\) e em \(y\), considerando apenas uma vez aqueles elementos com multiplicidade maior que \(1\);
set.intersect(x,y): interseção dos conjuntos \(x\) e \(y\), que corresponde ao conjunto dos elementos presentes simultaneamente em \(x\) e \(y\);
set.difference(x,y): conjunto da diferença entre os conjuntos \(x\) e \(y\), consistindo no conjunto de todos os elementos de \(x\) que não estão em \(y\);
x == y ou x != y: testa se dois conjuntos \(x\) e \(y\) são iguais ou se são diferentes, respectivamente;
c in y: pertencimento, ou seja, testa se \(c\) é um elemento do conjunto \(y\);
set.symmetric_difference(x, y): é o conjunto dos elementos que estão ou em \(x\) ou em \(y\), mas não está em ambos simultaneamente.
# operações com conjuntos# ilustrativasy =set([1,2,3,3])x = {3,4,5}set.union(x,y)x.union(y)x # não modifica xset.intersection(x,y)set.difference(x,y)x == yx != yt =tuple(set((1,2,3,3))) # removendo duplicados de uma tuplattype(t)y =set([1,2,3])x = {3,4,5}set.symmetric_difference(y,x)
{1, 2, 3, 4, 5}
{1, 2, 3, 4, 5}
{3, 4, 5}
{3}
{4, 5}
False
True
(1, 2, 3)
tuple
{1, 2, 4, 5}
Outras opções de operações básicas com conjuntos são as seguintes:
y.issubset(x): retorna True se \(y\) está contido ou é igual ao conjunto \(x\);
x.issuperset(y): retorna True se \(x\) contém ou é igual ao conjunto \(y\);
x.isdisjoint(y): retorna True se \(x\) e \(y\) não tiverem elementos comuns, ou seja, se a interseção for um conjunto vazio.
# outras operações com conjuntosx = {1,2,3,4,5}y = {1, 3, 5}# y está contido em xy.issubset(x)# x contém yx.issuperset(y)# se x e y são disjuntosx.isdisjoint(y)
True
True
False
7.5 Alguns Problemas de Probabilidade
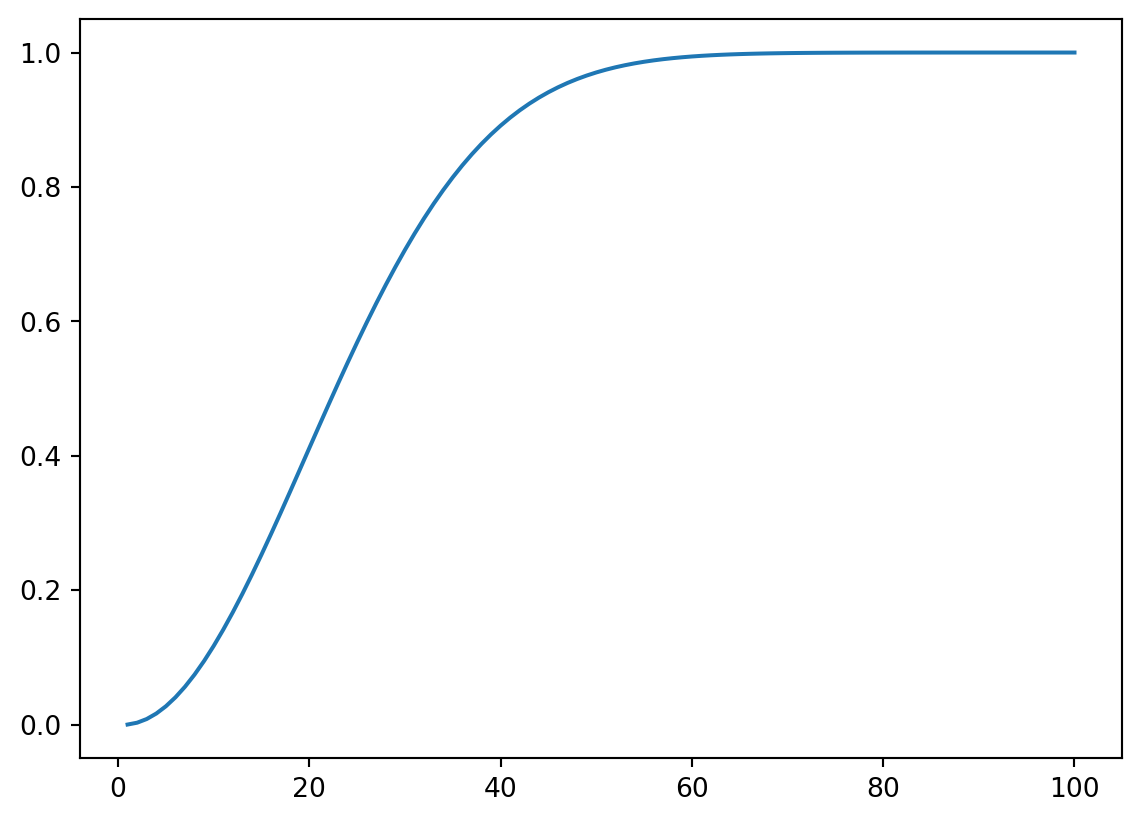
Vamos apresentar alguns casos particulares como o caso das coincidências de aniversários. Para a coincidência de aniversários, vamos considerar a coincidência de nascimento de um grupo de \(n\) pessoas na mesma data e que o ano tem \(365\) dias. Consideramos também que a distribuição dos nascimentos ao longo dos anos dos aniversários é aleatória uniforme, o que é uma forte suposição. A probabilidade de que nenhuma pessoa tenha a mesma data de nascimento (evento \(A\)) em um grupo de \(n\) pessoas é: \[\begin{align*}
P(A) =& \dfrac{A_{365,n}}{365^n}=\dfrac{365!}{(365-n)!365^n}.
\end{align*}\]
Desejamos a probabilidade do evento complementar, que é dada por \(P(A^c)=1-P(A)\). Logo, \[\begin{align*}
P(A^c) =& 1-\dfrac{A_{365,n}}{365^n}=1-\dfrac{365!}{(365-n)!365^n},
\end{align*}\]
que é a probabilidade de haver pelo menos uma coincidência de aniversários na mesma data.
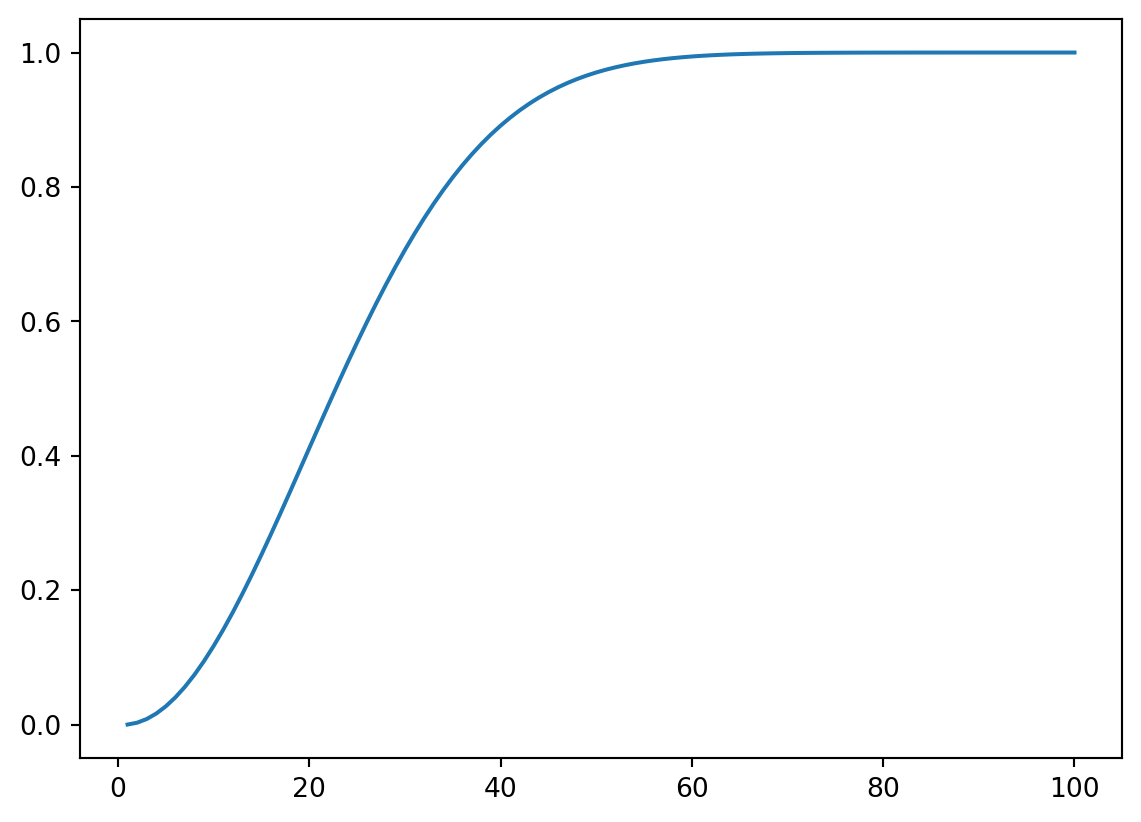
Implementamos duas formas. Na primeira usamos a fórmula completa. Tomamos o logaritmo (usamos a função gammaln da scipy.special) e ao final recuperamos tomando o exp do resultado. Na segunda alternativa usamos a biblioteca math, em que o total de arranjos \(A_{365,n}\) é obtido pelo comando math.perm(365, n).
O programa da primeira alternativa em Python é:
import numpy as npimport matplotlib.pyplot as pltfrom numpy.lib.scimath import logfrom numpy import expfrom scipy.special import gammaln# Uso do log of gama para obter o log do fatorialdef ca(n):# invertendo o log (i.e. exp)return1- exp(gammaln(365+1) - gammaln(365-n+1) -n*log(365) )n = np.arange(1, 100+1)# Gráficoplt.plot(n, ca(n))plt.show()
Nossa segunda implementação é:
# coincidência de aniversários# probabilidadesimport mathdef pca(n):iftype(n) ==int: n = [n] log365 = math.log(365) pc = np.empty(0)for k inrange(len(n)): pc=np.append(pc,1-exp(math.log(math.perm(365, n[k]))-n[k]*log365))return pcn = np.arange(1, 100+1)# Gráficoplt.plot(n, pca(n))plt.show()
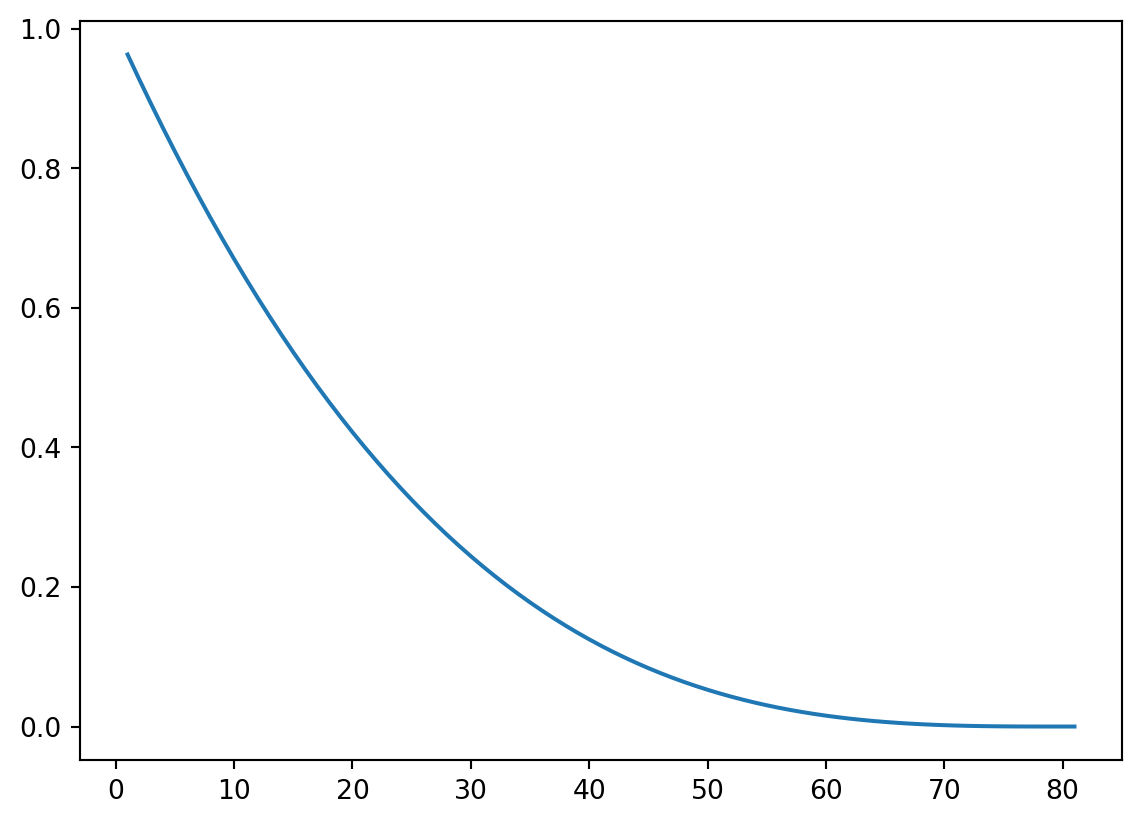
No segundo exemplo, vamos considerar a probabilidade de que uma comissão de tamanho \(m\) ao ser retirada de um grupo de tamanho \(n\) aleatoriamente não contenha representantes de um grupo existente específico de tamanho \(k\) entre os \(n\) elementos do grupo todo. Essa probabilidade é: \[\begin{align*}
P(\textrm{Não ser representado}) =& \frac{\binom{n-k}{m}}{\binom{n}{m}}.
\end{align*}\]
O programa Python foi implementado e ilustramos com o exemplo dos senadores do Brasil, que possui representantes das diferentes unidades federativas brasileiras. No Brasil temos \(n = 27\times 3\) senadores, ou seja, \(81\) senadores no total, sendo \(3\) de cada estado ou do Distrito Federal. Se vamos formar uma comissão aleatória de \(m=10\) senadores, qual é a probabilidade de que uma unidade federativa qualquer contendo \(k=3\) senadores não seja representada. Vimos por meio da análise da fórmula anterior que temos \(\binom{n}{m}\) maneiras diferentes de sortear comissões de tamanho \(m\) em \(n\) elementos do grupo todo. Se eliminarmos do total \(n\), os \(k\) que serão excluídos da composição da comissão, sobram \(n-k\) que podem ser amostrados \(m\) a \(m\). Assim, o número de comissões sem os \(k\) do grupo considerado é \(\binom{n-k}{m}\). A razão entre estas duas quantidades nos fornece a probabilidade desejada. O script com o exemplo dos senadores está apresentado a seguir.
# Probabilidade de uma comissão de m pessoas# não ter representante de um subgrupo de tamanho # k quando retirada uma comissão de tamanho m de # um grupo contendo n elementos, k < n e m <= n-kfrom scipy import special as spsdef pnr(n , m, k): pr = sps.comb(n-k, m) / sps.comb(n, m)return pr# Exemplon =27*3# número de senadores no Brasil, 81 (3 em cada estado ou DF)m =10# comissão de m delesk =3# um estado qualquer fixado não ser representado pnr(n,m,k)m =range(1, 81+1)plt.plot(m, pnr(n,m,k))plt.show() # probabilidade de MG e DF # não serem representados na comissãok =6m =10pnr(n,m,k)
np.float64(0.6698898265353962)
np.float64(0.44129815640475195)
Nosso próximo exemplo refere-se às probabilidades em uma mão de pôquer, construindo as possibilidades e probabilidades. Neste jogo podemos ter uma mão sem nada (sem pares, sem dois pares, sem trincas, etc.), uma com um par, uma com dois pares, uma com uma trinca, uma com uma sequência (qualquer de naipe), uma com flush (diferentes valores que não estão em sequência do mesmo naipe), uma com um full house (trinca e par), uma com o four (quadra), uma com uma sequência do mesmo naipe e uma sequência real do mesmo naipe (royal flush - do 10 ao Ás).
O número de possibilidades totais de distribuir \(52\) em um sorteio de \(5\) cartas (uma mão) é: \[\begin{align*}
\binom{52}{5}=& \dfrac{52!}{5!(52-5)!}=2.598.960.
\end{align*}\]
Para obtermos uma mão sem valor, temos que entender que o baralho é constituído de \(52\) cartas, sendo \(13\) valores das cartas (Ás, \(1\), \(2\), \(\cdots\), \(10\), Valete, Dama e Rei) e \(4\) naipes para cada valor (espadas, paus, ouros e copas). O número de possibilidades de uma mão de cinco cartas (sorteio de \(5\) cartas sem reposição) conter uma mão sem valor, ouseja, sem pares, sem trincas, sem quadras, sem sequências de naipes diferentes ou sem sequências do mesmo naipe é:
ou seja, é o número de cartas de diferentes valores com qualquer um dos \(4\) naipes \(\binom{13}{5}4^5\), subtraído de todas as possibilidades das sequências de naipes diferentes \(10\times 4^5\) e das possibilidades de ter cartas de diferentes valores com o mesmo naipe \(4\binom{13}{5}\). Este valor deve ser adicionado das dez possíveis sequências para cada um dos naipes \(4\times 10\). Esta adição se dá em razão de termos retirado as possibilidades de de ter cartas de diferentes valores com o mesmo naipe, que incluí as \(10\) sequências do mesmo naipe possíveis e novamente foi retirada quando eliminamos as possibilidades de termos \(5\) cartas de valores diferentes com o mesmo naipe, que incluí as \(10\) sequências do mesmo naipe possíveis. Daí precisamos adiciona-las, uma vez que elas foram retiradas duas vezes.
em que \(\binom{13}{1}\) escolhe o valor do par, \(\binom{4}{2}\) escolhe os naipes para o par, \(\binom{12}{3}\) escolhe entre os \(12\) valores remanescentes (não escolhido para o par) e \(4^3\), escolhe os naipes dos \(3\) valores diferentes do par.
em que \(\binom{13}{1}\) escolhe o valor do primeiro par, \(\binom{4}{2}\) escolhe os naipes para o primeiro par, \(\binom{12}{1}\) escolhe o segundo par entre os \(12\) valores remanescentes, \(\binom{4}{2}\) escolhe os naipes para o segundo par e \(\binom{11}{1}\) escolhe os valores entre os \(11\) valores remanescentes (não escolhido para os \(2\) pares) e \(4\), escolhe os naipes do valor diferente dos dois pares.
em que \(\binom{13}{1}\) escolhe o valor da tripla, \(\binom{4}{3}\) escolhe os naipes para a tripla, \(\binom{12}{2}\) escolhe os \(2\) valores entre os \(12\) valores remanescentes, \(4^2\) escolhe os naipes para estes valores.
em que \(10\) escolhe entre as \(10\) possíveis sequências (do Ás ao \(5\), do \(2\) ao \(6\), até do \(10\) ao Ás) e o \(4^5\) escolhe os naipes de cada valor. O resultado incluí as sequências do mesmo naipe, que devem ser retiradas, que correspondem à \(10\times 4\) (sequências de mesmo naipe incluindo as reais).
em que \(\binom{13}{5}\) escolhe os \(5\) diferentes valores entre os \(13\) e \(4\) escolhe um dos naipes para os \(5\) valores. O resultado incluí as sequências do mesmo naipe, que devem ser retiradas, que correspondem à \(10\times 4\) (sequências de mesmo naipe incluindo as reais).
em que \(\binom{13}{1}\) escolhe o valor para a trinca, \(\binom{4}{3}\) escolhe os naipes da trinca, \(\binom{12}{1}\) escolhe o valor do para entre os \(12\) valores remanescentes e \(\binom{4}{2}\) escolhe os naipes da dupla.
em que \(\binom{13}{1}\) escolhe o valor para a quadra que necessariamente terá uma de cada naipe, \(\binom{12}{1}\) escolhe um valor para a carta remanescente dos \(12\) valores restantes e \(4\) escolhe um dos naipes da carta remanescente, que não é o da quadra.
Para as sequências do mesmo naipe (straight flush):
\[\begin{align*}
10\times 4 - 4,
\end{align*}\]
pois são \(10\) sequências para um dos \(4\) naipes, subtraída das \(4\) sequências reais entre elas, do \(10\) ao Ás de cada um naipe entre os quatro naipes possíveis.
A sequência real (royal straight flush): tem uma única sequência possível do \(10\) ao Ás para cada um dos quatro naipes, totalizando \(4\) possíveis sequências reais.
O programa a seguir cria um dataframe com todas essas contagens e calcula as probabilidades dividindo-as pelo número total de combinações:
#Mão de pôquer# probabilidadesimport pandas as pdimport numpy as npfrom scipy import special as spspoker = {'none': sps.comb(13,5)*4**5-10*4**5-4*sps.comb(13,5) +10*4,'pair': 13*sps.comb(4,2)*sps.comb(12,3)*4**3,'two.pairs': sps.comb(13,2)*sps.comb(4,2)**2*11*4,'triple': 13*sps.comb(4,3)*sps.comb(12,2)*4**2,'straight': 10*4**5-10*4,'flush': 4*sps.comb(13,5) -10*4,'full.house': 13*sps.comb(4,3)*12*sps.comb(4,2),'four': 13*sps.comb(4,4)*12*4,'straight.flush': 10*4-4,'royal.flush': 4 }sum(poker.values()) - sps.comb(52,5) # conferirpokermão =list(poker.keys())possibilidades =list(poker.values())datapoker = pd.DataFrame({'mão': mão, 'possibilidades': possibilidades})datapoker['probabilidades'] =list(poker.values()) / sps.comb(52,5)datapokersum(datapoker['probabilidades'])
Nosso próximo exemplo refere-se à probabilidade da máxima diferença de uma lista enumerada ordenada. Obter o maior gap (salto) (diferença máxima) entre dois números consecutivos no sorteio sem reposição de \(m\) números entre os \(n\) primeiros inteiros de \(1\) a \(n\), para \(m<n\). No Python, o comando np.diff(x), retorna as diferenças entre números consecutivos da lista x.
O programa a seguir, usa a função checkgap para retornar a máxima diferença de um interador qualquer. A função maxgap, recebe \(n\), \(m\) e \(k\) e calcula as probabilidades de cada caso. Para isso ela percorre todas as combinações geradas por combinations retornando o máximo de cada combinação obtida em y e com o comando mean(y == k) é obtida a probabilidade exata de \(P(X=k)\), sendo \(X\) a variável que representa a maior diferença entre números inteiros consecutivos de uma amostra sem reposição de tamanho \(m\) obtida entre \(n\) números inteiros, para \(m\) de \(1\) a \(n\) e \(k\) o valor da máxima diferença (valor da variável aleatória) para o qual queremos calcular a probabilidade de ocorrência. Se \(m=2\), então a máxima diferença será considerada a diferença consecutiva, pois a diferença em cada resultado do espaço amostral é única, em razão de termos amostras de tamanho \(2\).
# Max gap probabilidadesfrom itertools import combinations import pandas as pddef checkgap(cmb): x = np.diff(cmb)returnmax(x)def maxgap(n, m, k):if m <=1or m > n:print('m deve estar entre 1 e n!')return comb =list(combinations(range(1,n+1), m)) y = np.empty(0)for cmb in comb: y = np.append(y,checkgap(cmb))return np.mean(y == k)# função para todo o suportedef maxgapsx(n, m):if m <=1or m > n:print('m deve estar entre 1 e n!')return comb =list(combinations(range(1,n+1), m)) y = np.empty(0)for cmb in comb: y = np.append(y,checkgap(cmb)) res = {'x':[],'P(X=x)':[]} for k inrange(1,n-m+2): res['P(X=x)'].append(np.mean(y == k)) res['x'].append(k)return pd.DataFrame(res)# exemplo de uson =6m =3k =2maxgap(n,m,k)maxgapsx(n,m)
np.float64(0.4)
x
P(X=x)
0
1
0.2
1
2
0.4
2
3
0.3
3
4
0.1
Nosso último exemplo é para a probabilidade das somas das faces no lançamento de \(n\) dados e da diferença em valor absoluto das faces no lançamento de \(2\) dados. Para este caso, podemos usar uma versão similar, ou aplicando a função contag anteriormente apresentada ou aplicando a função product da biblioteca intertools. Optamos por usar a função contag da classe cont.
Com uso de alguns pequenos detalhes adicionais, obtivemos os resultados para os dois casos. O segundo caso, da diferença, por razões óbvias, são resultantes do lançamento de apenas \(2\) dados. Nos dois casos apresentamos também os resultados das probabilidades obtendo todas as possibilidades que corresponde ao espaço amostral do experimento aleatório. Temos uma função para obter uma probabilidade para um valor específico da variável aleatória e outra para todos os valores de probabilidade relativos ao suporte da variável aleatória, nos dois casos, o da soma de \(n\) dados e o da diferença de dois dados. Os resultados estão apresentados no script a seguir:
# Probabilidades para o lançamento de# n dados e obtenção da soma e também# para a diferença absoluta de 2 dados# somafaces: retorna P(X=x)# depende da class contdef somafaces(n, x):if x<n or x>6*n:print('x deve estar entre n e 6n!')return res = Cont() perm = res.contag(6, n) y = np.empty(0)for pmb in perm: y = np.append(y,np.sum(pmb))return np.mean(y == x)def somafacessx(n):if x<n or x>6*n:print('x deve estar entre n e 6n!')return res = Cont() perm = res.contag(6, n) y = np.empty(0)for pmb in perm: y = np.append(y,np.sum(pmb)) res = {'x':[],'P(X=x)':[]} for k inrange(n,6*n+1): res['P(X=x)'].append(np.mean(y == k)) res['x'].append(k)return pd.DataFrame(res)# Probabilidades da diferença entre # duas faces de dois dados equilibrados# em módulo - retorna P(X=x), X=|i-j|def difabs2faces(x):if x<0or x>5:print('x deve estar entre 0 e 5!')return res = Cont() perm = res.contag(6, 2) y = np.empty(0)for pmb in perm: y = np.append(y,abs(np.diff(pmb)))return np.mean(y == x)# Probabilidades da diferença entre # duas faces de dois dados equilibrados# em módulo - retorna P(X=x), para todo# o suporte de xdef difabs2facessx():if x<0or x>5:print('x deve estar entre 0 e 5!')return res = Cont() perm = res.contag(6, 2) y = np.empty(0)for pmb in perm: y = np.append(y,abs(np.diff(pmb))) res = {'x':[],'P(X=x)':[]} for k inrange(0,5+1): res['P(X=x)'].append(np.mean(y == k)) res['x'].append(k)return pd.DataFrame(res) # Exemplon =4x =4print('P(X =',x,') = ',somafaces(n,x)) dist = somafacessx(n)distsum(dist['P(X=x)']) # checandoprint('P(X =',x,') = ',difabs2faces(x))difabs2facessx()
P(X = 4 ) = 0.0007716049382716049
x
P(X=x)
0
4
0.000772
1
5
0.003086
2
6
0.007716
3
7
0.015432
4
8
0.027006
5
9
0.043210
6
10
0.061728
7
11
0.080247
8
12
0.096451
9
13
0.108025
10
14
0.112654
11
15
0.108025
12
16
0.096451
13
17
0.080247
14
18
0.061728
15
19
0.043210
16
20
0.027006
17
21
0.015432
18
22
0.007716
19
23
0.003086
20
24
0.000772
1.0
P(X = 4 ) = 0.1111111111111111
x
P(X=x)
0
0
0.166667
1
1
0.277778
2
2
0.222222
3
3
0.166667
4
4
0.111111
5
5
0.055556
7.6 Exercícios
Obter uma função para obter por meio de simulação Monte Carlo as probabilidades dos lançamentos de \(n\) dados e obtenção da soma e também para as diferenças em módulo entre as faces nos lançamentos de dois dados. Para fazer isso escolha um grande número de repetições e em cada uma delas simule os resultados dos lançamentos dos dados. Obtenha os resultados das variáveis aleatórias e ao final calcule as proporções de cada ocorrência, conforme fizemos de forma exata anteriormente. Estas proporções são estimativas empíricas das probabilidades almejadas.
Obtenha também por Monte Carlo as probabilidades empíricas de uma mão de pôquer, simulando um grande número de mãos. Para isso é preciso criar um baralho, que pode ser feito com um dicionário e depois amostrar as mãos de cinco cartas e calcular as probabilidades empíricas de cada possível resultado. Confrontar com as probabilidades exatas obtidas neste capítulo. O que você espera que ocorra com essa comparação quando aumenta-se o número de simulações?