Neste capítulo, pretendemos apresentar os conceitos básicos de bootstrap de uma forma bastante simples. Vamos fazer algumas funções simples em alguns casos particulares.
8.1 Introdução
Um dos principais temas envolvendo os métodos computacionalmente intensivos e, talvez, o maior responsável pela popularidade desses métodos é a técnica bootstrap. O método bootstrap envolve reamostragens com reposição da amostra original. Inspirado na teoria da amostragem, o bootstrap é utilizado para a realização de testes de hipótese, estimação de parâmetros por intervalos e estimação de erros padrões.
A grande vantagem de se utilizar os métodos de reamostragens, como o bootstrap, para realizar inferência é quando não conhecemos a distribuição de probabilidade da população e o modelo normal não é adequado para os dados ou resíduos. O problema surge, quando violamos as condições assumidas para a aplicação de um teste ou obtenção de um intervalo ou região de confiança.
Neste capítulo, estudaremos os métodos bootstrap para realizar inferência sobre parâmetros de interesse.
8.2 Bootstrap Não-Paramétrico
Bootstrap não-paramétrico: a ideia é realizar reamostragem da amostra original. Seja amostra aleatória de tamanho \(n\), \(Y_1\), \(Y_2\), \(\ldots\), \(Y_n\), de uma população com distribuição desconhecida e cujo interesse é um parâmetro \(\theta\), podemos obter uma série de reamostragem com reposição de tamanho \(n\) e estimar o parâmetro de interesse por uma função \(\hat{\theta}\) das amostras obtidas.
Essa série de estimativas obtidas é finita e representa uma amostra da distribuição do estimador, permitindo que possamos fazer inferência sobre \(\theta\). Se pudéssemos obter a distribuição de amostragem de \(\hat{\theta}\) diretamente da teoria de amostragem, poderíamos fazer inferências sobre \(\theta\) sem a necessidade de utilizar bootstrap. Para isso, devemos conhecer a distribuição de probabilidade de \(Y_j\), \(j\)\(=\)\(1\), \(2\), \(\ldots\), \(n\) e, a partir dela, deduzirmos a distribuição de amostragem da função de interesse \(\hat{\theta}\).
Nem sempre isso é possível, principalmente se não conhecemos a distribuição de probabilidade da variável aleatória que estamos amostrando. Para a maior parte dos modelos probabilísticos, teorias exatas não são conhecidas ou são intratáveis analiticamente. Nesse caso, usamos a distribuição de probabilidade empírica, pela qual atribuímos a cada uma das observações amostrais a probabilidade \(1/n\);
A ideia do bootstrap é substituir a distribuição desconhecida da população pela distribuição empírica. Por essa razão, que denominamos esse método de bootstrap não-paramétrico. Ao obtermos um série finita de reamostragens de mesmo tamanho da amostra original e construirmos uma amostragem da distribuição do estimador, estamos realizando um processo de mímica em relação à teoria de amostragem.
Esse processo se baseia no fato de que a amostra obtida da população contém toda a informação disponível dessa população subjacente. Então, ela passa a representar a “população” para o processo de reamostragem.
Efron (1979) foi o pesquisador que organizou as teorias a respeito desse método e conectou o bootstrap não-paramétrico com as técnicas estatísticas para estimar erros, aceitas desde os anos de \(1930\), tais como jackknife e o método delta. Tanto a técnica bootstrap quanto os métodos de permutação assumem apenas que as variáveis aleatórias atendam ao princípio de serem permutáveis (exchangeable), que é uma suposição mais fraca que sejam independentes e identicamente distribuídas. Por permutáveis (intercambiáveis) devemos entender que a distribuição de probabilidade de quaisquer \(k\) observações consecutivas (\(k\)\(=\)\(1\), \(2\), \(\ldots\), \(n\)) não se altera quando a ordem das observações é trocada por meio de alguma permutação.
O algoritmo geral das reamostragens bootstrap, para estimar um pa-râ-me-tro \(\theta\) desconhecido, cuja distribuição de probabilidade é \(f\) (de \(Y\)), considerando, ainda, que o estimador \(\hat{\theta}\) é uma função dos valores amostrais, ou seja, \(\hat{\theta}\)\(=\)\(g(Y_1\), \(Y_2\), \(\ldots\), \(Y_n)\), é dado por:
atribuir massa de probabilidade \(1/n\) para cada observação amostral \(Y_j\), \(j\)\(=\)\(1\), \(2\), \(\ldots\), \(n\), criando a distribuição de probabilidade empírica \(\hat{f}\);
gerar amostras aleatórias com reposição da distribuição de probabilidade empírica \(\hat{f}\), denominada de amostra de bootstrap e dada por \(\tilde{Y}_1\), \(\tilde{Y}_2\), \(\ldots\), \(\tilde{Y}_n\);
calcular uma estimativa de \(\hat{\theta}\) por \(\tilde{\theta}\), usando a amostra de bootstrap no lugar da amostra original, da seguinte forma \(\tilde{\theta}\)\(=\)\(g(\tilde{Y}_1\), \(\tilde{Y}_2\), \(\ldots\), \(\tilde{Y}_n)\);
repetir os passos \(2\) e \(3\)\(B\) vezes.
O número de reamostragens foi denotado por \(B\) e a escolha de valores adequados conforme a situação será discutida posteriormente. A inferência que pretendemos realizar depende da distribuição desconhecida de \(\hat{\theta}\)\(-\)\(\theta\). Quando aplicamos o algoritmo anterior, obtemos uma amostra Monte Carlo, da distribuição de bootstrap, da quantidade \(\tilde{\theta}\)\(-\)\(\hat{\theta}\). Se \(n\) for suficientemente grande, pelas ideias do método bootstrap, extremamente comprovadas e aceitas atualmente, esperamos que as duas distribuições sejam aproximadamente idênticas.
8.3 Estimação
Para estimar parâmetros de uma população, a técnica bootstrap é uma excelente alternativa, principalmente se a distribuição não for a normal, ou outra distribuição, cujos processos de estimação sejam bem fundamentados teoricamente, como, por exemplo, a estimação de proporções binomiais \(p\). Se o método bootstrap for aplicado a esses casos, não será um problema, pois os resultados serão equivalentes ao da teoria clássica.
No entanto, se as suposições de um processo de estimação clássico forem violadas, em geral, os métodos bootstrap resultarão em processos de estimação com melhores propriedades. Inicialmente, devemos entender que os métodos bootstrap não melhoram as estimativas pontuais, mas fornecem mecanismos apropriados para estimar os erros padrões, intervalos de confiança e a distribuição de amostragem do estimador, por mais complexo que seja esse estimador.
8.3.1Erro padrão:
Para a estimação do erro padrão de um estimador \(\hat{\theta}\) de um parâmetro \(\theta\), devemos obter a distribuição bootstrap desse estimador, conforme descrito no algoritmo anteriormente apresentado. Assim, se considerarmos uma amostra aleatória \(Y_1\), \(Y_2\), \(\ldots\), \(Y_n\) de tamanho \(n\) da população de interesse, que depende de um parâmetro \(\theta\), que pretendemos estimar, então aplicamos o algoritmo anterior e obtemos uma amostra bootstrap de tamanho \(B\) da distribuição desse estimador.
Se a amostra for \(\tilde{\theta}_1\), \(\tilde{\theta}_2\), \(\tilde{\theta}_3\), \(\ldots\), \(\tilde{\theta}_B\), podemos estimar o erro padrão de \(\hat{\theta}\) por \[
S_{\hat{\theta}} = \sqrt{\frac{1}{B-1} \sum_{j=1}^B \left(\tilde{\theta}_j - \bar{\tilde{\theta}} \right)^2} = \sqrt{\frac{1}{B-1}\left[\sum_{j=1}^B \tilde{\theta}_j^2 - \frac{\left(\sum_{j=1}^B \tilde{\theta}_j\right)^2}{B} \right]},
\tag{8.1}\] em que \[
\bar{\tilde{\theta}}= \dfrac{\displaystyle \sum_{j=1}^B \tilde{\theta}_j}{B}.
\]
Depreendemos da expressão (Equation 8.1), que o erro padrão do estimador de \(\theta\) é o desvio padrão da distribuição bootstrap desse estimador. Se, entretanto, o parâmetro \(\theta\) for a média \(\mu\) da distribuição de probabilidade amostrada, podemos simplificar a expressão do estimador do erro padrão da média amostral \(\bar{Y}\), pois, nesse caso, não precisamos da amostra bootstrap do estimador.
Da teoria estatística, sabemos que o erro padrão da média amostral \(\bar{Y}\) é dado por \(S_{\bar{Y}}\)\(=\)\((1/n)^{1/2}S\), sendo \(S\) dado por \[
S= \sqrt{\frac{1}{n-1} \sum_{j=1}^n (Y_j-\bar{Y})^2}=\sqrt{\frac{1}{n-1}\left[\sum_{j=1} Y_j^2 - \frac{\left( \sum_{j=1}^n Y_j\right)^2}{n}\right]}.
\tag{8.2}\]
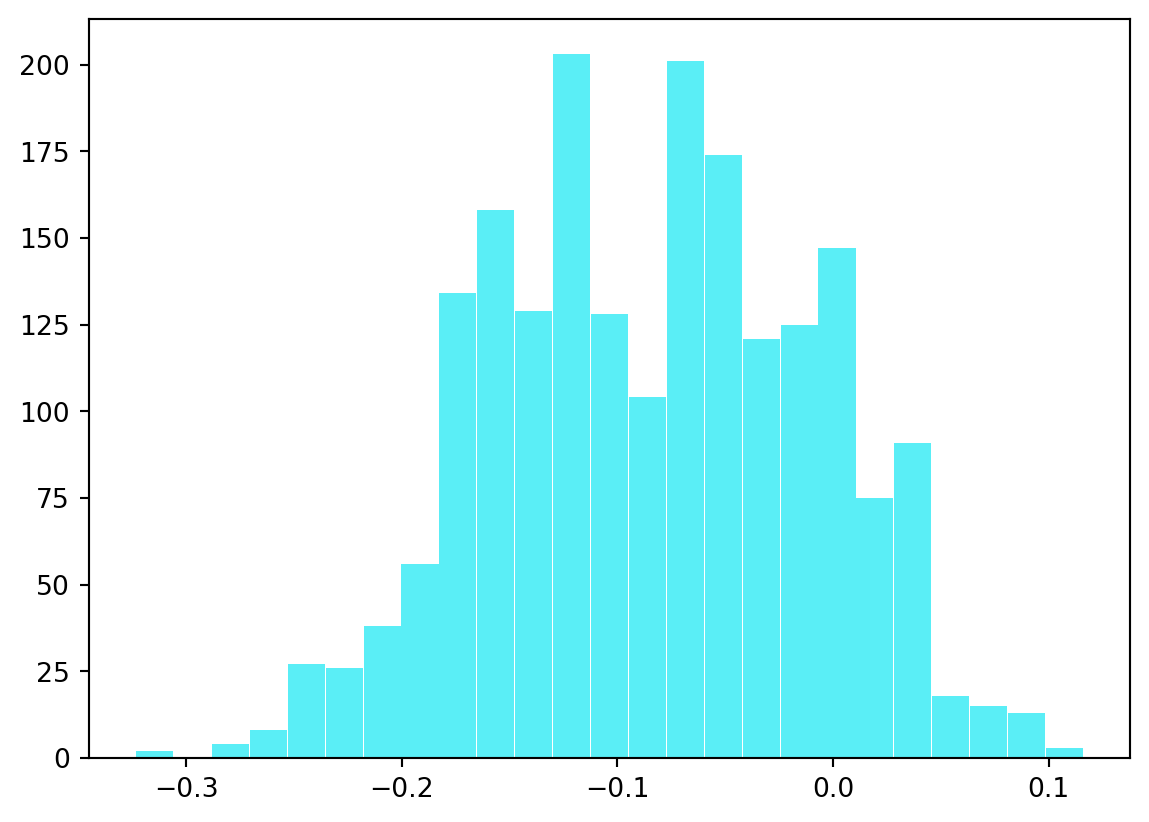
import numpy as npimport matplotlib.pyplot as pltimport random# função para retornar a medianadef est_med(x): y = np.sort(x) n =len(x)if n%2==0: est = (y[n//2-1] + y[(n+2)//2-1]) /2else: est = y[(n+1) //2-1] return est # função para o mínimodef est_min(x):return np.min(x) # função para o máximodef est_max(x):return np.max(x) # função para fazer uma reamostragem bootstrap# e aplicar o estimador genérico est, recebendo # x uma lista numpydef sampleOneBoot(x, est, *args): y = random.choices(x, k =len(x)) estm = est(y, *args)return estm# função para obter a distribuição de bootstrapdef dist_boot(x, est, B =2000, *args): dist = np.empty(0)for i inrange(B): dist = np.append(dist, sampleOneBoot(x, est, *args))return dist# função para obter o erro padrão do estimadordef stderr_est(x, est, B =2000, *args): result = dist_boot(x, est, B, *args) se_boot = np.std(result) est_boot = est(x, *args)return {"Estimativa": est_boot, "Erro padrão": se_boot}# estimar mediana normaln =300B =2000x = np.random.normal(size=n) dist = dist_boot(x, est_med)plt.clf() # limpar o gráficograf=plt.hist(dist,bins='auto',color='#14e8f3',rwidth=0.98,alpha=0.7) #histograma print('Média: ',np.mean(dist), 'e Desvio padrão: ', np.std(dist, ddof=1))res_med = stderr_est(x, est_med, B)for key, value in res_med.items():print(f"{key}: {value}")# valor teórico: aprox. (pi/2)^0.5*sigma/n^0.5print((np.pi/2)**0.5*1/n**0.5)# mínimo de uma normalres_min = stderr_est(x, est_min, B)for key, value in res_min.items():print(f"{key}: {value}")# máximo de uma normalres_max = stderr_est(x, est_max, B)for key, value in res_max.items():print(f"{key}: {value}")
Devemos explorar no bootstrap a possibilidade de correção de viés para estimadores viesados. Sabemos da teoria clássica que o viés \(\delta\) de um estimador \(\hat{\theta}\) é definido por \[
\delta_{\hat{\theta}} = E(\hat{\theta}) - \theta;
\tag{8.3}\]
Como na distribuição de bootstrap de um estimador \(\hat{\theta}\), a média representa a esperança em (Equation 8.3) e o estimador \(\hat{\theta}\) na amostra original, faz o mesmo papel de \(\theta\) na população, podemos estimar o viés por \[
\tilde{\delta}_{\hat{\theta}} = \bar{\tilde{\theta}} - \hat{\theta}. \tag{8.4}\]
É comum pensarmos que \(\bar{\tilde{\theta}}\) seria o estimador corrigido para viés, o que não é verdade. Podemos obter um estimador ajustado por \[
\begin{aligned}
\hat{\theta}_{\textrm{aj.}}=& \hat{\theta} - \tilde{\delta}_{\hat{\theta}} =\hat{\theta} -\bar{\tilde{\theta}} + \hat{\theta} \nonumber\\
=& 2\hat{\theta} - \bar{\tilde{\theta}};
\end{aligned} \tag{8.5}\]
Na sequência, abordaremos alguns dos diferentes tipos de intervalos de confiança usualmente empregados com o método denominado bootstrap não-paramétrico.
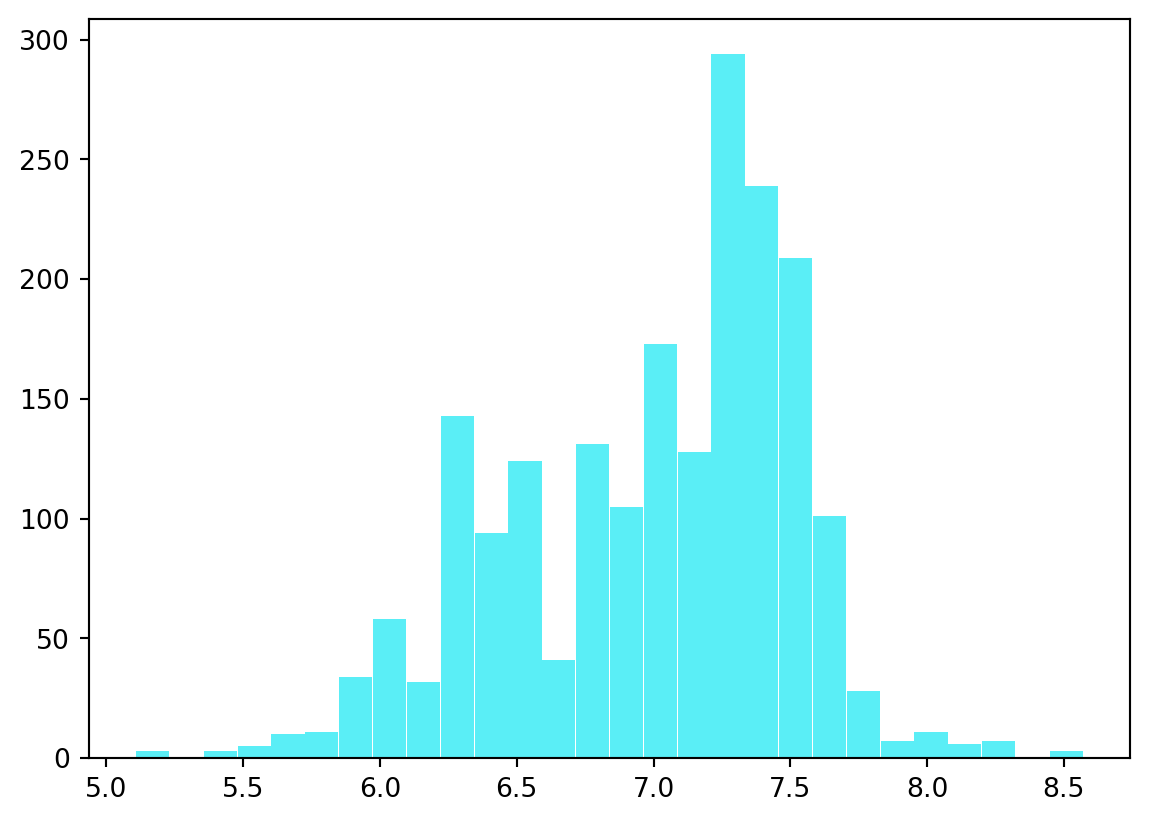
# função para obter o erro padrão do estimador# e aplicar a correção de viésdef stderr_vies_est(x, est, B =2000, *args): result = dist_boot(x, est, B, *args) se_boot = np.std(result) est_boot = est(x, *args) mean_boot = np.mean(result) vies_boot = mean_boot - est_boot est_nvies = est_boot - vies_bootreturn {"Estimativa": est_boot, "Erro padrão": se_boot, \"Viés ": vies_boot, "Est. Não Viesada ": est_nvies}# estimar mediana exponencial e erro padrãoimport scipy as spn =300B =2000lamb =0.1x = np.random.exponential(scale =1/ lamb, size = n) dist = dist_boot(x, est_med)plt.clf() # limpar o gráficograf=plt.hist(dist, bins='auto',color='#14e8f3',rwidth=0.98,alpha=0.7) # histograma res_med = stderr_vies_est(x, est_med, B)for key, value in res_med.items():print(f"{key}: {value}")# mediana teóricasp.stats.expon.ppf(0.5, scale =1/ lamb)
Estimativa: 7.007593744756914
Erro padrão: 0.4822953932811149
Viés : 0.021955279505346148
Est. Não Viesada : 6.985638465251568
np.float64(6.931471805599453)
8.3.3 Intervalo de Confiança Padrão de Bootstrap
Em algumas ocasiões, podemos assumir que a distribuição de bootstrap do estimador \(\tilde{\theta}\) é normal. Isso ocorre em situações especiais de amostragem: como o caso específico de \(\tilde{\theta}\) ser a média amostral \(\bar{Y}\) em amostragem da distribuição normal e, também, no caso de amostras grandes \(n\) em consequência do teorema do limite central.
Sabemos que \(\tilde{\theta}\) é uma função dos elementos amostrais e, em consequência disso, para muitas dessas funções, a distribuição normal ocorre como decorrência do teorema do limite central. Infelizmente, a experiência tem mostrado que esse intervalo é via de regra geral, muito pobre, no sentido de que as suas propriedades não são preservadas.
A principal propriedade requerida de um intervalo de confiança é que ele possua probabilidade de cobertura igual ao valor nominal de confiança \(1-\alpha\) adotado, o que, em geral, não é atendida nesse caso. A ideia é admitir o efeito do teorema do limite central: \[
\tilde{\theta} \dot{\sim} N\left(\hat{\theta},\, S_{\hat{\theta}}^2\right),
\tag{8.6}\] em que, onde se encontra o símbolo \(\dot{\sim}\), deve se ler “se distribui aproximadamente como”, \(\hat{\theta}\) é o valor do estimador na amostra original e \(S_{\hat{\theta}}\) é o estimador do erro padrão de \(\hat{\theta}\), obtido na distribuição bootstrap.
Em consequência de (Equation 8.6}), podemos construir o intervalo bootstrap padrão com confiança de aproximadamente \(1-\alpha\) por \[
IC_{1-\alpha} (\theta): \left[\hat{\theta} - Z_{1-\alpha/2}S_{\hat{\theta}} ;\, \hat{\theta} - Z_{\alpha/2}S_{\hat{\theta}}\right], \tag{8.7}\] em que \(Z_{\alpha/2}\) e \(Z_{1-\alpha/2}\) são os quantis da distribuição normal padrão. O intervalo de confiança (Equation 8.7), como já havíamos comentado, possui probabilidade de cobertura, em geral, inferior ao valor nominal de \(100(1-\alpha)\%\).
Podemos melhorar este intervalo obtendo os limites do intervalo de confiança usando um estimador corrigido para viés. . O resultado para este caso é: \[ IC_{1-\alpha} (\theta): \left[\hat{\theta}_{\textrm{aj.}} - Z_{1-\alpha/2}S_{\hat{\theta}} ;\, \hat{\theta}_{\textrm{aj.}} - Z_{\alpha/2}S_{\hat{\theta}}\right],
\tag{8.8}\] em que \(\hat{\theta}_{\textrm{aj.}}\) é dado em (Equation 8.5).
# função para obter o IC padrão # com correção de viésdef ic_padrao_cv_boot(x, est, B =2000, alpha =0.05, *args): res = dist_boot(x, est, B, *args) est_boot = est(x, *args) se_boot = np.std(res) mean_boot = np.mean(res) vies_boot = mean_boot - est_boot me = sp.stats.norm.ppf(1- alpha /2) * se_boot li = est_boot - vies_boot - me ls = est_boot - vies_boot + mereturn {'estimativa': est_boot, 'erro padrão': se_boot, \'viés': vies_boot, 'limite inferior': li, 'limite superior': ls}# exemplo para a mediana exponencialn =30B =2000lamb =0.1alpha =0.05x = np.random.exponential(scale =1/ lamb, size = n) res_med = ic_padrao_cv_boot(x, est_med, B, alpha)for key, value in res_med.items():print(f"{key}: {value}")# mediana teóricasp.stats.expon.ppf(0.5, scale =1/ lamb)
A seguir, apresentamos um exemplo para a distribuição gama. Nos subsequentes exemplos, usaremos a mesma amostra da mesma distribuição.
. . .
# Exemplo para a mediana da gaman =30B =2000alpha =0.05a =0.5x = np.random.gamma(a, size = n) res_med = ic_padrao_cv_boot(x, est_med, B, alpha)for key, value in res_med.items():print(f"{key}: {value}")# mediana teóricasp.stats.gamma.ppf(0.5, a)
8.3.4 Intervalo de Confiança Baseado em Percentis Bootstrap
É um dos mais interessantes, pois sua obtenção é, no mínimo, curiosa. Assumir, normalidade da distribuição bootstrap é subutilizar o potencial do método. Entretanto, podemos pensar que existe uma função \(\phi\) monótona, tal que \(\phi(\tilde{\theta})\) tenha distribuição normal.
Se obtivermos a distribuição de bootstrap dessa função, obtida pela sua aplicação em cada reamostragem com reposição da amostra original, podemos obter seu desvio padrão \(S_{\phi(\tilde{\theta})}\). Como essa distribuição, obtida considerando um número finito \(B\), é uma amostra de uma distribuição normal, os intervalos obtidos por \[
IC_{1-\alpha} (\phi(\theta)): \left[\phi(\hat{\theta}) - Z_{1-\alpha/2}S_{\phi(\tilde{\theta})} ;\, \phi(\hat{\theta}) - Z_{\alpha/2}S_{\phi(\tilde{\theta})}\right]
\] ou diretamente ordenando-se a amostra de tamanho \(B\) da distribuição bootstrap e tomando-se os seus percentis \(100(\alpha/2)\%\) e \(100(1-\alpha/2)\%\), devem se equivaler na medida em que \(B\)\(\rightarrow\)\(\infty\).
Segundo Efron e Tibshirani (1993), a transformação \(\phi\) que irá levar a normalidade sempre existe. Dessa forma, o intervalo de confiança para \(\theta\), uma vez que \(\phi\) é uma função monótona, é dado por \[
IC_{1-\alpha} (\theta): \left[\phi^{-1}\left(\phi(\hat{\theta}) - Z_{1-\alpha/2}S_{\phi(\tilde{\theta})}\right) ;\, \phi^{-1}\left(\phi(\hat{\theta}) - Z_{\alpha/2}S_{\phi(\tilde{\theta})}\right)\right],
\tag{8.9}\] em que \(\phi^{-1}\) é a função inversa de \(\phi\).
Podemos verificar de (Equation 8.9) que, o intervalo de confiança para o parâmetro na escala original é obtido pela transformação inversa dos limites do intervalo obtidos na escala transformada. Utilizamos em (Equation 8.9) a transformação inversa dos limites obtidos a partir dos percentis normais padrão e da média e variância da distribuição de bootstrap para os obtenção dos limites do intervalo de confiança na escala original. Entretanto, poderíamos ter utilizado uma versão que usaria a transformação inversa dos percentis \(100(\alpha/2)\%\) e \(100(1-\alpha/2)\%\) obtidos diretamente da distribuição de bootstrap na escala transformada.
Isso pode ser feito, em virtude do que acabamos de comentar, ou seja, que a distribuição de bootstrap obtida pela transformação, exceto pelo fato de ser uma amostra finita, é normal e os dois intervalos na escala transformada se equivalem assintoticamente.
Posto dessa forma, parece ser fácil obter um intervalo como o apresentado em (Equation 8.9). Isso não é verdade, pois necessitaríamos obter a função \(\phi\), que levaria a uma distribuição de bootstrap normal. Encontrar tal função para cada caso real é uma tarefa inexequível. Por outro lado, não precisamos conhecer tal função, basta pressupor sua existência.
Como os valores do intervalo, obtidos na escala transformada, quando mapeados na escala original são equivalentes aos percentis \(100(\alpha/2)\%\) e \(100(1-\alpha/2)\%\) da distribuição de bootstrap de \(\tilde{\theta}\), então a construção do intervalo de confiança por esse método é trivial. Esse resultado é extremamente interessante e foi preponderante para o sucesso dos métodos de estimação bootstrap. Como afirmam Efron e Tibshirani (1993), podemos entender o método dos percentis para a obtenção do intervalo de confiança, como sendo um algoritmo automático de incorporação de tais transformações que levam à normalidade. Para que fique mais claro, podemos dizer que os limites obtidos de (Equation 8.9) correspondem exatamente ao intervalo baseado em percentis da distribuição de bootstrap na escala original, portanto não precisamos conhecer a transformação que irá conduzir a distribuição de bootstrap à normalidade, mas apenas pressupor sua existência!
Para aplicar o intervalo de confiança baseado em percentis bootstrap, devemos aplicar o algoritmo anteriormente apresentado. Obtemos: \(\tilde{\theta}_1\), \(\tilde{\theta}_2\), \(\tilde{\theta}_3\), \(\ldots\), \(\tilde{\theta}_B\).
Devemos ordenar esses valores, obtendo as estatísticas de ordem por: \(\tilde{\theta}_{(1)}\), \(\tilde{\theta}_{(2)}\), \(\tilde{\theta}_{(3)}\), \(\ldots\), \(\tilde{\theta}_{(B)}\). Em seguida, podemos obter o intervalo de confiança a partir dessa função de distribuição empírica, obtendo os percentis \(100(\alpha/2)\%\) e \(100(1-\alpha/2)\%\). Assim, construímos o intervalo de confiança baseado em percentis bootstrap por \[
IC_{1-\alpha} (\theta): \left[\tilde{\theta}_{(k_1)} ;\, \tilde{\theta}_{(k_2)}\right],
\tag{8.10}\] em que \(k_1\)\(=\)\(\lfloor(B+1)(\alpha/2)\rfloor\) e \(k_2\)\(=\)\(\lfloor(B+1)(1-\alpha/2)\rfloor\), ou seja, são os maiores inteiros que não são maiores que \((B+1)(\alpha/2)\) e \((B+1)(1-\alpha/2)\), respectivamente; \(\tilde{\theta}_{(k_1)}\) é o percentil \(100(\alpha/2)\%\) da função de distribuição bootstrap empírica; e \(\tilde{\theta}_{(k_2)}\), o percentil \(100(1-\alpha/2)\%\) da função de distribuição bootstrap empírica.
Esse intervalo possui propriedade melhores que o anterior e funciona bem na maioria dos casos mais simples. Entretanto, existem alternativas melhores. Veremos, a seguir, alguns outros tipos de intervalos que são melhores que os dois primeiros, embora em algumas situações o método percentil é superior a alguns deles.
Uma grande vantagem do intervalo percentílico é que ele possui a propriedade de respeitar a transformação, ou seja, os limites desse intervalo obedecem ao domínio do parâmetro que está sendo estimado, o que, em alguns métodos, não ocorre.
# função para obter o IC Percentisdef ic_perc_boot(x, est, B =2000, alpha =0.05, *args): res = dist_boot(x, est, B, *args) est_boot = est(x, *args) se_boot = np.std(res) mean_boot = np.mean(res) vies_boot = mean_boot - est_boot li, ls = np.percentile(res, [alpha/2*100, (1-alpha/2) *100])return {'estimativa': est_boot, 'erro padrão': se_boot, \'viés': vies_boot, 'limite inferior': li, 'limite superior': ls}# Exemplo para a mediana da gamaB =2000alpha =0.05res_med = ic_perc_boot(x, est_med, B, alpha)for key, value in res_med.items():print(f"{key}: {value}")# mediana teóricasp.stats.gamma.ppf(0.5, a)
Variação do intervalo baseado em percentis bootstrap, resulta da obtenção da distribuição de \(\tilde{\theta}\)\(-\)\(\hat{\theta}\), que representa, simplesmente, a versão bootstrap da distribuição de amostragem de \(\hat{\theta}\)\(-\)\(\theta\). Para grandes valores de \(B\), \(\tilde{\theta}\)\(-\)\(\hat{\theta}\) converge em distribuição para \(\hat{\theta}\)\(-\)\(\theta\).
Se considerarmos que existe uma função \(\phi(\tilde{\theta}\)\(-\)\(\hat{\theta})\) monótona, capaz de conduzir a normalidade, então seria necessário obtermos, apenas, os percentis \(100(\alpha/2)\%\) e \(100(1-\alpha/2)\%\) da distribuição original, pois eles mapeiam valores equivalentes na escala normal transformada.
Se denotarmos por \(\tilde{\delta}^{(\alpha/2)}\) e \(\tilde{\delta}^{(1-\alpha/2)}\) esses percentis na escala original, então \[ P\left[\tilde{\delta}^{(\alpha/2)}\le \tilde{\theta} - \hat{\theta}\le\tilde{\delta}^{(1-\alpha/2)}\right]= 1-\alpha\\
P\left[\tilde{\theta}^{(\alpha/2)} - \hat{\theta} \le \tilde{\theta} - \hat{\theta} \le \tilde{\theta}^{(1-\alpha/2)}- \hat{\theta}\right]= 1-\alpha.\]
Os limites da afirmativa probabilística em (Equation 8.11) são os limites de uma intervalo de \(100(1\)\(-\)\(\alpha)\%\) de confiança de bootstrap básico, dado por \[
IC_{1-\alpha} (\theta): \left[2\hat{\theta} - \tilde{\theta}^{(1-\alpha/2)} ;\, 2\hat{\theta} - \tilde{\theta}^{(\alpha/2)}\right].
\tag{8.12}\]
Esse intervalo pode também ser visto como o intervalo de confiança \(t\) de bootstrap, que será o próximo a ser estudado, quando o erro padrão em cada reamostragem for considerado igual a unidade. As quantidades \(\tilde{\theta}^{(1-\alpha/2)}\) e \(\tilde{\theta}^{(\alpha/2)}\) do intervalo (Equation 8.12) são, respectivamente, os percentis \(\tilde{\theta}_{(k_1)}\) e \(\tilde{\theta}_{(k_2)}\) do intervalo (Equation 8.10) baseado em percentis. Observamos que o presente método é apenas uma variação do método percentil.
# função para obter o IC Padrão Básicodef ic_basic_boot(x, est, B =2000, alpha =0.05, *args): res = dist_boot(x, est, B, *args) est_boot = est(x, *args) se_boot = np.std(res) mean_boot = np.mean(res) vies_boot = mean_boot - est_boot ls, li = np.percentile(res, [alpha/2*100, (1- alpha /2) *100]) li =2* est_boot - li ls =2* est_boot - lsreturn {'estimativa': est_boot, 'erro padrão': se_boot, \'viés': vies_boot, 'limite inferior': li, 'limite superior': ls}# Exemplo para a mediana da gamaB =2000alpha =0.05res_med = ic_basic_boot(x, est_med, B, alpha)for key, value in res_med.items():print(f"{key}: {value}")# mediana teóricasp.stats.gamma.ppf(0.5, a)
8.3.6 Intervalo de Confiança Bootstrap com Correção de Viés Acelerado
Os intervalos de confiança bootstrap, anteriormente apresentados, possuem deficiências relativas às probabilidades de cobertura, pelo menos, em parte das situações práticas. Outro método de obtenção de intervalos bootstrap possui qualidades melhores do que os intervalos anteriores, embora possua maiores dificuldades de obtenção: bootstrap com correção de viés acelerado, \((BC_a)\).
Este é o método ideal a ser utilizado. O método \(BC_a\) é obtido de forma semelhante ao método bootstrap percentil, porém ao se determinar os percentis da distribuição empírica de bootstrap \(\tilde{\theta}_{(1)}\), \(\tilde{\theta}_{(2)}\), \(\tilde{\theta}_{(3)}\), \(\ldots\), \(\tilde{\theta}_{(B)}\) do estimador, duas quantidades \(\hat{a}\) e \(\hat{z}_0\) são necessárias também. As quantidades \(\hat{a}\) e \(\hat{z}_0\) são definidas como aceleração e correção de viés;.
O intervalo de confiança baseado em percentis bootstrap com correção de viés acelerado, \(BC_a\), é dado por \[ IC_{1-\alpha} (\theta): \left[\tilde{\theta}_{(k_1)} ;\, \tilde{\theta}_{(k_2)}\right],
\tag{8.13}\] em que \(k_1\)\(=\)\(\lfloor(B+1)p_1\rfloor\) e \(k_2\)\(=\)\(\lfloor(B+1)p_2\rfloor\), ou seja, são os maiores inteiros que não são maiores que \((B+1)p_1\) e \((B+1)p_2\), respectivamente; \(\tilde{\theta}_{(k_1)}\) é o percentil \(100(p_1)\%\) da função de distribuição bootstrap empírica; e \(\tilde{\theta}_{(k_2)}\), o percentil \(100p_2\%\) da função de distribuição bootstrap empírica.
Para valores conhecidos de \(\hat{a}\) e \(\hat{z}_0\), os valores de \(p_1\) e \(p_2\), usados para determinar as ordens \(k_1\) e \(k_2\) do valor de \(\tilde{\theta}\) na distribuição empírica de bootstrap, conforme apresentado em (Equation 8.13), são determinados por \[
p_1= \Phi\left(\hat{z}_0 + \dfrac{\hat{z}_0+z_{\alpha/2}}{1-\hat{a}\left[\hat{z}_0+z_{\alpha/2}\right]}\right) \textrm{ e } p_2= \Phi\left(\hat{z}_0 + \dfrac{\hat{z}_0+z_{1-\alpha/2}}{1-\hat{a}\left[\hat{z}_0+z_{1-\alpha/2}\right]}\right), \tag{8.14}\] em que \(\Phi(x)\) é a função de distribuição da normal padrão avaliada no valor \(x\) e \(z_{\alpha/2}\) e \(z_{1-\alpha/2}\) são os quantis \(100(\alpha/2)\%\) e \(100(1-\alpha/2)\%\) dessa mesma distribuição, respectivamente.
Se tanto \(\hat{a}\) quanto \(\hat{z}_0\) forem nulos, os valores de \(p_1\) e \(p_2\) serão, respectivamente, \(\alpha/2\) e \(1-\alpha/2\), como pode ser facilmente deduzido de (Equation 8.14). Nesse caso, os intervalos \(BC_a\), expressão (Equation 8.13) e bootstrap percentil, expressão (Equation 8.10), são equivalentes. Valores não nulos dessas quantidades, modificam os limites do intervalo (Equation 8.13) e reduzem algumas deficiências do intervalo percentílico (Equation 8.10), conforme afirmam Efron e Tibshirani (1993).
O valor de \(\hat{z}_0\) é definido como o quantil da normal padrão cuja probabilidade acumulada é dada pela proporção de estimativas na distribuição de bootstrap que é menor que a estimativa de \(\theta\) na amostra original. Esse valor reflete a discrepância que existe entre a mediana da distribuição de \(\tilde{\theta}\) e a mediana da distribuição de \(\hat{\theta}\), expressa em unidades normais padrão.
Assim, definimos \(\hat{z}_0\) por \[
\hat{z}_0= \Phi^{-1}\left(\dfrac{\displaystyle \sum_{i=1}^B I\left(\tilde{\theta}_i <\hat{\theta}\right)}{B}\right),
\tag{8.15}\] em que \(\Phi^{-1}(p)\) é a inversa da função de distribuição da normal padrão avaliada em \(p\) entre \(0\) e \(1\) e \(I(\cdot)\) é a função indicadora que retorna \(1\) se o valor de seu argumento for verdadeiro e \(0\), se for falso.
O valor \(\hat{z}_0\) será zero somente se a proporção de valores da distribuição de bootstrap que são inferiores a \(\hat{\theta}\) for igual a \(50\%\). O valor de \(\hat{a}\) pode ser calculado utilizando estimativas jackknife do parâmetro de interesse.
Admitamos que o estimador \(\hat{\theta}\) seja obtido por uma função do vetor de observações amostrais \(\mathbf{Y}\)\(=\)\([Y_1\), \(Y_2\), \(\ldots\), \(Y_n]^\top\) por \(\hat{\theta}\)\(=\)\(g(\mathbf{Y})\). Se eliminarmos a \(i\)-ésima observação \(Y_i\) teremos o vetor \(\mathbf{Y}_{(i)}\)\(=\)\([Y_1\), \(Y_2\), \(\ldots\), \(Y_{i-1}\), \(Y_{i+1}\), \(\ldots\), \(Y_n]^\top\), que corresponde ao vetor original sem a \(i\)-ésima observação. O estimador jackknife é obtido aplicando-se essa mesma função ao vetor resultante sem a \(i\)-ésima observação, sendo dado \(\hat{\theta}_{(i)}\)\(=\)\(g(\mathbf{Y}_{(i)})\).
Se calcularmos a média das \(n\) estimativas jackknife, obtidas com a eliminação de cada uma das \(n\) observações originais, por \[
\bar{\hat{\theta}}_{(.)}= \dfrac{\displaystyle \sum_{i=1}^n \hat{\theta}_{(i)}}{n},
\] a aceleração \(\hat{a}\) pode ser obtida por \[
\hat{a} = \dfrac{\displaystyle \sum_{i=1}^n\left(\bar{\hat{\theta}}_{(.)} - \hat{\theta}_{(i)}\right)^3 }{6\left[\displaystyle \sum_{i=1}^n\left(\bar{\hat{\theta}}_{(.)} - \hat{\theta}_{(i)}\right)^2\right]^{3/2}}.
\tag{8.16}\]
A quantidade \(\hat{a}\) é chamada de aceleração porque representa a taxa de mudança do erro padrão de \(\hat{\theta}\) em relação à mudança dos valores do parâmetro verdadeiro \(\theta\) (EFRON; TIBSHIRANI, 1993). Esse intervalo de confiança, possui duas vantagens: a) resultar em estimativas dos limites do intervalo de confiança dentro do espaço paramétrico, ou seja, possui a propriedade de respeitar a transformação; e b) fornecer resultados muito precisos, no sentido de que as probabilidades de cobertura \(P(\theta<\tilde{\theta}_{(k_1)})\)\(=\)\(\alpha/2\) e \(P(\theta>\tilde{\theta}_{(k_2)})\)\(=\)\(\alpha/2\) são observadas com precisão de segunda ordem, enquanto o método percentil bootstrap possui precisão de primeira ordem apenas.
# função auxiliar para cômputo da aceleraçãodef aceler(x, est, *args): n =len(x) ai = np.empty(0)for i inrange(n): yi = np.delete(x, i) ai = np.append(ai, est(yi, *args)) ab = np.mean(ai) a = np.sum((ab - ai)**3)/(6*(np.sum((ab - ai)**2))**1.5) return a# função para obter o IC com correção de viés aceleradodef ic_cva_boot(x, est, B =2000, alpha =0.05, *args): res = dist_boot(x, est, B, *args) est_boot = est(x, *args) p = np.sum(res < est_boot) / B z0 = sp.stats.norm.ppf(p) z1 = sp.stats.norm.ppf(alpha /2) z2 = sp.stats.norm.ppf(1- alpha /2) a = aceler(x, est, *args) aux = z0 + (z0+z1)/(1-a*(z0+z1)) p1 = sp.stats.norm.cdf(aux) aux = z0 + (z0+z2)/(1-a*(z0+z2)) p2 = sp.stats.norm.cdf(aux) se_boot = np.std(res) mean_boot = np.mean(res) vies_boot = mean_boot - est_boot li, ls = np.percentile(res, [p1 *100, p2 *100])return {'estimativa': est_boot, 'erro padrão': se_boot, \'viés': vies_boot, 'limite inferior': li, 'limite superior': ls}# Exemplo para a mediana da gamaB =2000alpha =0.05res_med = ic_cva_boot(x, est_med, B, alpha)for key, value in res_med.items():print(f"{key}: {value}")# mediana teóricasp.stats.gamma.ppf(0.5, a)
8.3.7 Intervalo de Confiança Bootstrap com Correção de Viés
Esse método é uma variação do método anterior, em que a aceleração \(\hat{a}\) é considerada nula. Nesse caso, o intervalo de confiança é obtido pela mesma expressão (Equation 8.14), embora os valores de \(p_1\) e \(p_2\) sejam calculados por \[
p_1= \Phi\left(2\hat{z}_0 + z_{\alpha/2}\right) \textrm{ e } p_2= \Phi\left(2\hat{z}_0 + z_{1-\alpha/2}\right), \tag{8.17}\] sendo \(\hat{z}_0\) obtido da mesma forma que foi descrito anteriormente, por intermédio da equação (Equation 8.15).
Esse método é particularmente interessante em algumas situações em que os valores de \(\hat{a}\) são difíceis de ser obtidos. Esses casos são discutidos em Efron e Tibshirani (1993). Entretanto, o método \(BC_a\) é, em geral, mais eficiente e deve ser preferido.
# função para obter o IC com correção de viésdef ic_cv_boot(x, est, B =2000, alpha =0.05, *args): res = dist_boot(x, est, B, *args) est_boot = est(x, *args) p = np.sum(res < est_boot) / B z0 = sp.stats.norm.ppf(p) z1 = sp.stats.norm.ppf(alpha /2) z2 = sp.stats.norm.ppf(1- alpha /2) aux =2* z0 + z1 p1 = sp.stats.norm.cdf(aux) aux =2* z0 + z2 p2 = sp.stats.norm.cdf(aux) se_boot = np.std(res) mean_boot = np.mean(res) vies_boot = mean_boot - est_boot li, ls = np.percentile(res, [p1 *100, p2 *100])return {'estimativa': est_boot, 'erro padrão': se_boot, \'viés': vies_boot, 'limite inferior': li, 'limite superior': ls}# Exemplo para a mediana da gamaB =2000alpha =0.05res_med = ic_cv_boot(x, est_med, B, alpha)for key, value in res_med.items():print(f"{key}: {value}")# mediana teóricasp.stats.gamma.ppf(0.5, a)
Entre algumas possibilidades, podemos utilizar scipy.stats.bootstrap no Python para aplicarmos os métodos de estimação intervalar bootstrap. A função bootstrap do scipy é dada por bootstrap(data, statistic, *, n_resamples=9999, batch=None, vectorized=None, paired=False, axis=0, confidence_level=0.95, alternative='two-sided', method='BCa', bootstrap_result=None, rng=None, random_state=None). Três métodos estão disponíveis, quais são: method{‘percentile’, ‘basic’, ‘BCa’}, sendo o BCa o método padrão. O programa a seguir mostra como obter o intervalo de confiança por este procedimento do scipy.
Os dados tem de ser transformados em uma tupla, antes de usar o método bootstrap. Veja o exemplo:
# Demonstrando o scipy.stats.bootstrap# Exemplo para a mediana da gamaB =2000alpha =0.05x = (x,) # dados devem estar numa tupla de arrayres_med = sp.stats.bootstrap(x, est_med, n_resamples=B, \ confidence_level=1-alpha, method='percentile')print(res_med.confidence_interval)res_med = sp.stats.bootstrap(x, est_med, n_resamples=B, \ method='basic', confidence_level=1-alpha)print(res_med.confidence_interval)res_med = sp.stats.bootstrap(x, est_med, n_resamples=B, \ method='BCa', confidence_level=1-alpha)print(res_med.confidence_interval)# mediana teóricasp.stats.gamma.ppf(0.5, a)